Clay Shirky at NYU Shanghai
とある記事 を読んでいたら Clay Shirky がコメントを寄せており、その肩書が "a professor at N.Y.U. Shanghai". このひと、いま上海に住んでるのか。やるな・・・そして NYU Shanghai なんてものがあるのだな。
少し前に Xiomi の本を出していたのも Shanghai 修行の成果なのだろうか。あまり熱心に宣伝している様子はないけれど。
とある記事 を読んでいたら Clay Shirky がコメントを寄せており、その肩書が "a professor at N.Y.U. Shanghai". このひと、いま上海に住んでるのか。やるな・・・そして NYU Shanghai なんてものがあるのだな。
少し前に Xiomi の本を出していたのも Shanghai 修行の成果なのだろうか。あまり熱心に宣伝している様子はないけれど。
少し前、OnePlus 3 を落としてスクリーンを派手に割ってしまった。修理依頼したので体験記。
落として割った夜、安い電話への買い替えやガジェット充な友達への物乞いを考えるも気が乗らず、冷静に考えたら修理できるんじゃね?とサポートサイトを見る。デバイスをオンラインで買っていた場合、そのときのアカウントでログインすると修理の申し込みができる。ので修理申し込み。
即日返事がくる through Zendesk. 落として割ったら無償保証外だけいい?というので了解する。二営業日以内に提携している Acer の修理センターから連絡がいくのでその指示に従ってデバイスを送れという。
結局三営業日後にメールで連絡あり。指定の電話番号に電話をし、支払いに使うクレジットカードの番号を口頭で伝えよ。不在の場合は折り返すという。うげー。折り返されたランダムな場所でカード番号を読み上げるのはイヤすぎる。しかし予想どおり電話には待ち行列がない。他の支払い方法にしてくれとメールを書くが、できないという冷たい返事。仕方なく三回時間を変えて電話し、ようやくつながる。
つながったあとはスムーズで、各種サポート番号や住所などを確認のうえカード番号を伝え、修理の handshake 完了。Fedex からデバイス発送。なお修理センターの住所は Texas だった。Shipping には時間がかかったものの、修理は即日行われ、すぐ帰ってきた。透明な保護ケースがおまけで送られてきたので、反省してつけている。
最初に申し込みから修理完了うけとりまで二週間くらい。修理費用は自分側の shipping いれて $100 ちょっと。電話でクレジットカード番号を伝えるところは辟易したけれど、それ以外はまあまあスムーズだった。
なお Zendesk では入れ替わり立ち替わり違う人が同じような連絡をよこし、サポート自体の練度は割と不安なかんじ。そのへんをけちっての低価格なんだね。まあサポートがまともな会社は Apple 以外に見たことないので、期待より悪くはない。
Matplotlib を使ったコードを写経しようとしたが 10 行くらいで発狂しそうになる。この API, 眺めてるときからクソだと思ってたけれど自分で書くのは更に苦痛。耐えられませぬ...
しかし今回は high level な API に逃げないと決めているので、なんとかこの人たちの気持ちを理解しようと公式のドキュメントを読んでみる。と、一定程度理解が深まり殺意も和らいだのでみんな読むと良いよ、という話。
まず Introduction から。「表面的には Matlab インスパイヤな API だけれど中は割と object oriented だよ」という。かすかな希望を抱いて次に Introductory Tutorial を一通り眺める。それから Artist Tutorial を読む。
わかること:
あのクソのような API たちもあくまでショートカットなのですよ・・・ちゃんとオブジェクトモデルあるよ・・・といわれると多少許してあげようという気になる。特にかっこいいデザインではないし Axes のモデルなんかは不必要に複雑だと思うけれども、理不尽というほどでもない。こんなもんだよなと諦めはついた。
まえに Coursera のクラスでさわった ggpot2 がかっこよすぎたせいでどうしても可視化 API への期待値があがってしまう。あそこまでかっこよくなくていいんだけど、せめでもうちょっとなんとかならなかったのか。でも Python は気の利いた API をつくるための文法が弱いよね。たとえば Ruby のようなブロック構文があったらだいぶ可愛くできるはずだけれど、Python に block はない。フル機能の lambda もない。R みたいに AST を quote/unparse することもできない。きびしい。
Plotnine のように ggplot を模倣するライブラリはあるから Python の言語機能が完全に力不足というわけでもないのだけれど (すくなくとも operator overloading はある)、一方で ORM みたいに多くのプログラマがよってたかって作りなおせるほど敷居の低いジャンルでもないから、Matplotlib のような kind of good enough なものが生き残ってしまうのだろうなあ。まあ Altair などを片目でひやかしつつしばらくは Matplotlib 修行します。はい。
Effectively Using Matplotlib という記事を見かけた。この人は常に object oriented API を使えと言っているなあ。そして Pandas の plot と Matplotlib を混ぜて使っている。自分はこの二つを混ぜられないと勝手に思い込んでいたけれど、たしかに Pandas で書きつつ Matplotlib でカスタマイズするのは良い手に思える。
Sequence Modeling: Recurrentand Recursive Nets.
それなりに面白かった。Sequence-to-Sequence とかもでてきて、おおコレが話にきいていたアレか、と思うなど。
CNN も RNN もなんとかして parameter sharing をしつつ構造に関する prior knowledge をネットワークに埋め込もうとしているという点が腑に落ちたのはこの本を読んで良かったところだと思う。系統だった理解というやつ。のはず。
RNN, 前にやった時は結局どうやってデータを食わすのかよくわからず frustration が溜まったけれど、その後 Keras や TF のサンプルを眺めてデータは適当にぶったぎって固定長(未満)にそろえてつっこむ、ということを理解して以来 demythify された。そういう practical matter は理論的な本でも一応説明してほしいよなあ。
そのほか:
古いコードの依存関係を整理するなか、"utils" というパッケージが依存関係の mess になっているのに気付く。Utils. そういえば昔はよく目にしたけれど、最近はあまり見なくなった。なぜかと考える。
プログラミング言語が強力になったのが理由の一つだろう。昔だったら Verb-er や NounUtils などと銘打ったクラスに追い出したくなる boilerplate ぽいコードが、今なら短くインラインで書ける。あるいは同じファイルの中に小さなクラスを定義するだとか適当に extension method を生やすとかでしのげるようになった。
あとは文法だけでなく標準ライブラリも充実した言語が増え、それまで各人が再発明していたコードが標準でついてくるようになった。これは言語デザインの主流が委員会ベースからコミュニティベースに移り、割と荒削りなものでも便利なら標準につけてしまうことが増えたおかげもある気がする。言語によるか。
理由2つめはオープンソースの普及。かつて Utils として書かれたようなコードは今ならだいたいサードパーティのオープンソースライブラリとして誰かが書いている。そもそも言語自体が大概オープンソースだから、標準ライブラリとサードパーティライブラリの境目も昔ほどはっきりしない。他人のコードに依存しすぎたせいでおこる left-pad 騒動 みたいな問題もないではない。でも総体としてutils 時代より間違いなく前進している。人気があるライブラリなら自分で書くより出来が良いことも多いし。
自分は "utils" を "manager" に匹敵する code smell と敵視していた時期があり、utils をどう解体すべきかについて意見があった。けれど今となっては manager と並んで一部の不幸な人以外にとってはどうでもいい話題だね。
以下、時代にとりのこされている人のための utils 解体講座。
utils とは要するに「名前や居場所を考えるのがめんどくさいコード置き場」であり、そういう雑さは規模が小さければ別にあっていいとおもう。が、量が増えてくると急速にデザインを腐敗されるのでどこかで真面目に切り分けないといけない。
Utils につっこまれるコードの代表格は、標準ライブラリやフレームワークの穴埋め役。本来ならそれらのライブラリに入っていて欲しかったけれど、入っていない機能たち。こういうコードは、自分のツリーの中に標準ライブラリやフレームワークを mirror したパッケージ構造を作って分類するのが定番。厳密に mirror するのが大げさすぎると感じるなら適当に簡略化してよい。あと java には java.util という台無しパッケージがあるのでこれは真似しない。Guava なり Scala なりもうちょっとマシな例に倣う。java.util というパッケージングはほんとにひどいとおもうけれども、20 年前の判断なので責める気にもならない。コレクションが util であることに人々が疑問を持たなかった時代。
Utils につっこまれるコードの別パターンは、自分のコードベースの既存パッケージにぴったりくるものがなく、とりあえず・・・とつっこまれたもの。気持ちはわかるけれど、まだ既存のパッケージに無理やりねじ込んでおく方が歪みが隠れなくて良いと個人的には思う。ある規模を超えたコードに utils のようなゴミ捨て場を作ってしまうと tragedy of commons が起きがち。
Messy なコードを整理したい立場からみると、こっちのとりあえずパターンは、ある程度機械的に扱える前のパターンより厄介。失敗したデザインを一つ一つ直していかないといけない。嫌がられつつ別のパッケージに移すのも場合によっては仕方ないと思う。責任転嫁。ゴミの可視化。
デザインの失敗は今も昔もある。でも utils という都合の良いゴミ捨て場のない近代的なコードベースはダメさが目に着きやすくて良い、のかもしれない。モダンなゴミ捨て場の姿には興味がある。どうなってんのかな。
またゴミスレを読んでしまった・・・
I met my wife because she was stuck in VI. I was a unix sysadmin in the early 90s, and she was a grad student. She came to me for help (like most of the 1st years did) because she couldn't get out of vi.
そして
And I met mine, while she needed help trying to copy paste in emacs. IDE users, you're doomed to stay single!
さらに
I wooed my wife by being able to solve a computer problem as well. Her laptop wouldn't boot, and she had a paper on the hard drive that needed to be submitted that day. "I have just the thing," I said, and I ran home to get my drive-to-USB adapter. Pulled her hard drive, recovered the paper, and printed it from my own laptop. The rest is history.
映像的には最後のが汗臭くていいな。
Scikit-learn の使い方が知りたくて読んだ。TensorFlow は cross validation とかを手伝ってくれないので別の道具がほしかったのと、 Keras が scikit learn 互換だと何かで読んたため。
Scikit-learn を知るには良かった。知りたかったこと (Pipeline の使い方や GridSearch などの話題) がきちんとカバーされていた。コードは割とちゃんとしていると思う。著者は scikit-learn にちょこっとパッチを書いたりもしているらしい。
Machine learning 自体の学習にはいまいち。アルゴリズムや数式の説明の仕方がよくないと思う。知ってる人の復習にしかならない。アルゴリズムの説明は飛ばし読み。そのほか Web アプリを作りましょう、みたいな話も飛ばし読み。最後にでてくる NN の話はスキップ。
Coursera ML の後すぐに読めばよかったと今更ながら思った。 Ensemble 系以外はだいたい同じ話題を扱っている。これを読んでから Kaggle をやっていたらもうちょっと手を動かせたかもしれない。
そのほか。
Matplotlib 習熟の必要性を感じた。今のところ自分は Pandas の DataFrame.plot() でなんとか可視化をやりすごして来たけれど、それより numpy の array をズバっと描けるようになった方が柔軟で便利そうだと文中に登場する数々の matplotlib チャートたちをみて思った。
NN で扱うようなメディアや非構造データ自体を plot することはあまりなさそうだけれど、loss の変化とか gradient の norm とか plot したいものはなにかとある。Tensorboard でもいいのかもしれないけど、記録をとるには Jupyter に埋め込める Matplotlib が必要そう。どうやって練習しようかね。この本のサンプルコードを写経でもすべきか・・・。
Scikit-learn. 一通り色々実装されてるのはいいんだけど、ほんとに NN と一緒に使えるのだろうか。なにかとデータを全部メモリに乗せたがるし、トレーニング結果の check-pointing もなさそうだし、いまいち頼りない感じがする。でもみんなこれ使ってるんだよね?なぞ。
微妙に腹が痛い。ストレスと疲労の組み合わせだろうか。安全をとって欠勤。
数年前に胃潰瘍を患って以来、体調不良の中でも胃痛を警戒するようになった。そのとき胃カメラで調べてもらったら、最新の胃潰瘍以外にも過去に2つ潰瘍があったと判明。むかし何度か激しい腹痛で寝込んだことがあったけれど、まさか潰瘍だったとはと無頓着さに呆れたのだった。
潰瘍は癌へと発展しやすく、かつ自分の父親は胃癌でなくなっている。そして胃カメラは日本ですら 9000 円くらいしたのでこっちで治療となったらいくらすることやら。 $1,000 ...よりは高そう。などの理由により要警戒。
こうした微妙な体調不良で仕事を休むのに、最近はなんとなく抵抗がある。なぜかと考えてみると、なんとなくサボり癖がついて休みがちになり、そのまま会社に行けなくなって解雇される未来を察している自分に気付いた。昔は解雇されたらされたでいいかと思っていたけれど、今は色々 liability がある割に仕事で大したことをできていないため自分の employee-bility に敏感。とはいえ上司の目や迫りくる締め切りを気にして仕事を休めない心配がまったくない身の上には感謝した方がいいのかもしれない。
I/O の talk より: TensorFlow Frontiers
TensorFlow がらみの新しい話。中でも Cloud TPU を GCE で使うデモがあった。I/O では Cloud TPU を大々的に売り込んでいたけれど、どうやってエンドユーザに公開するのか疑問だった。ハードウェアの仕様も非公開だしドライバのバイナリみたいのもなさそう。どう使うの?
デモによると、ユーザはまず専用のイメージの指定などしかるべきオプションで GCE のインスタンスをつくる。するとそのインタンスでは分散 TensorFlow のサーバみたいのが動く。なのでコードは GRPC を使った TensorFlow 標準の分散 API を使ってそのサーバにアクセスすればよい。という感じらしい。なるほど。
分散 TF をよくわかってないのでトレーニングデータを誰が読むのか想像がつかないけれど、もし remote node が直接 GCS/S3 あたりからデータを読めるなら Jupyter や Tensorboard は手元の laptop で動かし計算資源だけ GCE とかができるようになるかもしれない。期待。
更に高望みをするなら、将来的には fully managed なサービスとしてエンドポイントに接続したら適当に TensorFlow の計算資源が割り当てられるようになってほしいなあ。TensorFlow は Hadoop みたいな奴らと違い分散先では任意コードを実行できない。その点では BigQuery などの MPP に近いで multi-tenancy にやさしい。やる気になればできるような気もする。まあ計算資源の量を細かくコントロールしたいぶん MPP よりは大変そうだけれど。
そんな日に備えて TensorFlow のチュートリアルを再開しないとなあ・・・。
I/O の talk より: Open Source TensorFlow Models.
TensorFlow の人たちが公開している pre-trained なモデルを使って面白いことをしようという話。その中でも CNN の pre-trained model のうち最後のほうのレイヤだけを捨てて自分のデータセットでトレーニングし直すテクニックが面白かった。CS231N の lecture notes に同じ話題を扱った節がある。TensorFlow にもサンプルと解説が入っている。有名な話っぽい。
Goodfellow 本でもちらほら pre-training を議論するものの、それらは大体過去の話として扱われている。特に CNN の章には最近はぜんぶ train するのが主流と書いてある。たぶん state-of-the-art の結果を狙うならそれで正しいのだろうだけれど、金もデータもなく他人の成果にあやかりたい庶民の観点だと pre-trained なモデルを使い回せるならそれに越したことはない。
Transfer Learning, もっと cutting edge で難しい話題なのかと思っていた。でもこの例に限るとなかなかわかりやすいし実用的だね。
TensorFlow にもぽつぽつと pre-trained model はあるものの、この点 Caffe/Caffe2 は Model Zoo というのを保守していてえらい。NN のフレームワークとしては使えるモデルをいっぱい持っている方が良いと思うので TF にも見習って欲しいなあ。モデル欲しさにみんな Caffe 使うようになったらどうすんの。
Google やその他のクラウド業者と違って Facebook は AI を直接売り物にしていない。だから遠慮なくモデルをオープンにできるのかもしれない。戦略的に Caffe のモデルをバンバン公開してマインドシェアを狙う。Open Compute と同じアプローチか。
などと感心していたら、最新の成果たる CNN translation のモデルは Torch ベースだった。邪推してすまぬ・・・他の会社は隣の芝で、なんかすごい戦略を持ってるように見えるのだよ・・・。
それはさておき自分のデータセットでモデルを fine tune できるのだとすると、世間の画像認識 API みたいな切り口はちょっと制限が強すぎる気がする。将来は課金すると追加で training data を登録できるようになると面白いね。
ようやく子供のパスポートが届いた。
最初に書類を提出してから一ヶ月たった頃、おまえらの出した書類は親(我々)の身元を示すのに十分でないから追加で書類をだせと手紙がきた。将来同じようなトラブルがあった人が検索したときのために verbatim に書いておくと: "Please submit photocopies of file (5) or more personal documents, which are five (5) years or older." ... しかもこれらの書類には signature か photo, 更に issue date が入ってないといけないという。そんなものないんですけど。
5 年前なんて US にいないし、日本で発行された書類に署名なんて入ってない。てかそんなに沢山身分証明証もってない。仕方ないので条件を満たそうが満たすまいが構わず日米免許証住民票(翻訳つき)グリーンカードビザパスポートなどなどありったけの身元証明書類のコピーをとり、条件をみたす書類がない理由をしたためた手紙と一緒に提出した。で、また一ヶ月くらい待ってようやくできた次第。はーひやひやしたよまったく・・・。
なぜこんな仕打ちを受けたのだろうか。一説によれば、カルフォルニアの driver's license は例外的に身分証としての効力がないらしい(※要出典)ので、身分証明目的では他の書類を使うべきだった、のかもしれない。自分の予想は IRS の audit とおなじで確率的な bad luck だったというもの。
オンラインで調べても似たようなトラブルにあった日本人を発見できなかったし身の回りでも聞いたことのないトラブルだったので、参考のために記録しておく。
ところでパスポート申込書の最初の提出もまあまあ大変だった。USPS (郵便局) で申し込めることになっているのだけれど、近隣の USPS は予約で一杯。申し込みから二ヶ月くらい待たされる。
ゆこっぷ(おくさん)が調べたところ一部の USPS office は予約を受け付けず当日の申し込みを先着順でさばくというのでその一部の office に行ってみると、本日分の受付は終了しましたという。どうも毎日早朝に予約をする仕組みらしい。仕方ないので翌朝出直して二時間くらい並び、予約をとる。
予約をとっても自分のターンがきたタイミングでその場にいないと無視されてしまう仕組み。しかもそのターンの正確なタイミングはわからない。仕方ないので予想時刻のレンジ(申し込みから更に 3 時間後)を教わり、妻子は一旦家に帰し、その後は 最寄りのコーヒー屋まで45 分くらいかけて歩く(え!?)など周りになにもないど田舎の USPS office のそばでヒマをつぶし、時間がちかづいたタイミングでふたたび妻子と合流してまたしばらく待ち、申し込みを済ませた。なぜ妻子というか子が必要かというと本人の立ち会が必要だから。
自分は休暇中だったからなんとかなったけれど、この大変さは unbearable すぎ。どうなってるんだろうね。このあたりは異常に外国人比率が高い。米国人と比べ自分のような外国人の子供はまず確実にパスポートをつくる。そして citizenship をとった元外国人もパスポートをつくるだろう。だから人口に対して発行されるパスポートの数が多いのだろうな。そのせいで USPS の想定処理能力を超えているのか。想定してくれってかんじだが・・・。
なおそんな事情(?)を踏まえ、外国人の多い大企業であるところの勤務先には数ヶ月に一度出張パスポート受付サービスがやってくるのだった。
おもったほど新しい発見はなかった。NN4ML で読まされた LaNet や AlexNet の paper がすごいよく書けていたせいか、既にまあまあよく理解できていたっぽい。CNN って基本的なところはあまり難しくない割に強力で、お得感があるよね。
とはいえ復習としてはよかったし、理論的な位置づけも補強された。あと Neurosciene との関係についての節は読み物として面白かった。網膜の裏の神経というのはある種の CNN で、それがどんな kernel なのかを調べた人がいる、そしてその kernel によって学習される feature は CNN が学習してる feature と結構似てるんだよ、みたいな。やばい。
具体的なアーキテクチャの話が全然ないのはやや不満。rapidly moving だから本として記録しても仕方ないから、とかかいてあるけど、一個くらい実例の walk though をやってくれてもいいのにね。
あと CNN は kernel のサイズが画像サイズと独立だから異なるサイズの画像をつかって learning できるのだよ、みたいな話があって、しかしそんな例みたことないし想像もつかないなと調べてみたらちょっと大変そうだった。
Sundar が Quora で Chrome の質問に答えていたのに気がついた。2010. この頃はまだ割と下っ端だったんだなー・・・たぶん Chrome のいちばんえらい PM とかそういうかんじだったような気がする。下っ端はいいすぎか。それにしてもずいぶん出世したもんだなあ(えらそう)。ちなみにこの頃は WebKit のいちばん偉い人がふつうに HN で troll コメントをするなど牧歌的な時代でありました。
いやーめでたいね。諸事情で当分仕事では使えなそうな気配だが、それでもめでたい。どのくらいめでたいかというと Steve Yegee が思わず blog を書いてしまうくらいめでたい。
余暇で Kotlin をかいたあと仕事の古い Java に戻ると色々なフラストレーションを感じる。これは必要な痛みだと思う。以前に感じていたよりはっきりとした形でダメさを識別している。昔々 C++ が一番得意だった頃に C 言語をやらされたときのことを思い出す。あるいは元気だった頃の Java をしばらくさわってから C++ をさわったとき。最近だと Haskell 入門してから Rx をさわるとかも。
相対的に新しいものをさわってから古い世界に戻ると、古い世界に足りないものがはっきりとわかる。だからできる範囲で新しい世界のツールを backport しようとする。(古い例: C 言語でオブジェクト志向、Emacs でリファクタリング) そうした conceptual backports には不自然なものも多いけれど、古いテクノロジを新しい世代に引っ張っていくのは基本的にこうした backports でもある。
保守的なチームで働いていると新しいテクノロジを仕事で使う機会がなかなか来ないけれど、くじけずたまには新しいものを触っておかねばなあ。そして新しい概念をちまちまこっそり backport していきたい。
ソーシャルメディアなどをみているとなぜ Go なり Swift なりを採用しなかったのか企業政治残念、みたいなことを言ってる人がちょこっといるけれども、おまえら Android アプリのコード書いたことあんのかあるいは Android 本体のコード読んだことあんのか、と思う。なぜ Scala, Groovy じゃないのか、というなら百歩譲ってわからなくもないけれど。I/O 中はついウェブをしてしまったせいで無駄に精神衛生を損ね反省。
なおなぜ Scala や Groovy や Clojure じゃないのかは、まあ一通り試せばわかります・・・自分も Groovy でいいのではと思っていた時期がありました・・・ NYTimes が一時期 Groovy を使っていた(2014)けど, 遅くてやめた(2016)という話を思い出した。わかるよ。Java とっくに飽きたけど Groovy も思ったより厳しかったよな・・・。
本を読む数値目標を「単位期間あたり X 冊」みたいな形で決めるのと「単位期間あたり Y 時間」みたいに決めるのとはどっちがよいのだろうな。(本を読むべきなのか、という議論はさておくとして。)
自分は Goodfellow をもう一ヶ月半くらい読んでおり、それでもまだ道半ば。このペースでいくと年間に読める本の冊数は 3-4 冊くらいになる。一方で O'Reilly あたりのちょろい本ばかり読んでいても仕方ない。プログラミング言語やライブラリの入門みたいにちょろい本を読めば済むこともたくさんあるのでそれがダメとはまったく思わないけれど、ガチなやつも読みたいじゃん。冊数という目標はこの期待を反映しない。じゃあゆるふわ X 冊ガチ Y 冊、みたいに決めればいいかというと、これはいかにも細かすぎる。
一方で時間を決めるというのは自分がいまやっていることで、これはまあまあ機能している。
ただマンネリ化しやすい面もある。数字的に前に進んでいくものがないせいだろうか。あと確保している時間の質が悪いせいで本が全然読み進まないのに、それに気づけなかったりする。自分は去年 Doing Bayesian Data Analysis というのを三ヶ月くらいかけてちまちま読んでいたのだけれど、ほんっとに全然進まず 1/3 くらいで挫折した。が、今思えばこれは夜の疲れた頭で読んでいたせいもある気がする。時間だけを追跡すると、こういうフラストレーションを捉えられない。今は朝に通勤ランニングをした直後の1日で最も元気な時間を Goodfellow に割り当てており、おかげでちょっとくらいシグマとかインテグラルがでてきてもめげずに済んでいる。
とか考えると「常に何か読んでいる本があるようにする」くらいのゆるい目標をもっておき、定期的に振り返って「ああ N 冊も読んでがんばったな」とか逆にちょっと足りなかったな、などと状況に応じてやりかたを調整していけばいいのかもしれない。
Keras の作者が日本のテクノロジの悪口を言った話がなにかのオンラインメディアに取り上げられ、それを日本の IT ナショナリストが腐していた。後続の発言を見ると、Keras の作者は日本では国産のライブラリばかり使い Keras を使っていないことに苛立ちこうした発言に至った様子が伺える。
なんだかうんざりしてしまった。まず Keras や周辺ライブラリの普及がおもったより進まない日本 IT コミュニティへの苛立ちを表立ったところに帝国主義的な言い回しで書いてしまう Keras 作者の troll ぶりにがっかり。その心の狭さに Keras を使う気が少し削がれた。非英語圏なら自国贔屓は多かれ少なかれどこにでもある。日本なんてソフトウェアの世界ではほとんど存在感ないんだからほっとけばいいのに、なまじ日本語が読めるだけに目についてしまうのだろうか。
たとえば自分が Keras のバグをみつけてレポートしたり PR を送ったりしたとして、自分の nationality への蔑視を表立って口にしている人を相手にするのは気が重い。いわれのないハラスメントを受けそうで。まあ自分が Keras のバグをみつける可能性はほぼゼロなのでその心配はないとしても、Keras 情報を求めてソーシャルメディアを見ていたら自分の出身国の悪口がランダムに目に入ってくるかもしれないと思うと意欲を削がれる。
NN の higher level abstraction は現状ほぼ Keras 一択。ハラスメントの心配はほぼ杞憂だろうし日本の悪口で動じないくらいには nationality を detach できている外国暮らしの身。めげずに Keras を使うと思う。でも強い立場にいるライブラリの作者だからこそ弱小のことはそっとしといてほしいよね。
よりがっかりしたのは日本の IT ナショナリストの発言の方。はー。色々とみっともない・・・。
一瞥すればわかりとおり、この人は Keras 作者と対話する気は全くない。元の troll 発言を口実に昔話をしていい気分になったり、そういう話に呼応する人の関心を引いてナショナリストとしてのカルマを高めているだけ。書き手の会社は NN まわりの仕事もしているようなので、もしかしたら将来自社製のミドルウェアを売り込む際に Keras 作者への antipathy を引き合いに出したいのかもしれない...と、最後のは我ながら下品な憶測で、さすがにないと思うけれども。
Keras 作者の発言の文脈は、日本人もどうせそのうち Keras 使うようになるんでしょという話なわけで、そこに昔の栄光を引き合いに出して反論するのはまったく不毛。ナショナリストとして生産的でありたいなら、Keras 作者のバカにしている日本産のライブラリを競争力のある良いものに育てて見返すことに注力するとか、せめてその国産ライブラリの Keras に対する利点を議論するとかしてほしかった。テクノロジの世界で昔話しても仕方ないでしょ・・・。
まあナショナリストが一般に残念な発言をする傾向にあるのは仕方ないとしても、その記事に対する人々の反応が割と好意的なのが自分のうんざりにとどめをさした。ソーシャルメディア、この手の安っちいナショナリズムと相性良すぎ。おまえら!どうでもいい愛国美談に酔ってないで前を見ろ!がんばれ!
そんなかんじで朝から疲れてしまったけれど、書き出したら気が済んだ。日本のソフトウェア産業にはがんばってほしいもんです。ほんとに。
元ネタを読む。少しはわかった。なぜこれがすごく効くのか数学的に理解できたかというとまったくそんなことはないけれど、少なくともなにをしているかはわかったはず。大局的になんかするわけではなく、 BN のレイヤを挟むだけの局所的なものだとわかったのはよかった。単に normalize するだけでなく、その normalization を cancel するような謎のパラメタを学習させるところがすごいというか、ちょっと狂ってるなと思う。
それにしても実験結果が豪華。Dropout を過去のものにする(こともある)と主張するのもそれなりに説得力がある。ただ CNN の場合はこうしろだの色々実用上は繊細なところがある様子も伺える。使うとなったら真面目に読み直さないとダメそう。というかまあ、サンプルをコピペするんだろうな。
チートがてら TensorFlow の実装をみてみたら辛い感じ・・・。TF 固有の読みづらさは差し引くとして、まず Batch Renormalization という最新の成果が雑に突っ込まれ可読性を損ねている。そして mean と variance を moving average として更新している。え、そんな話だったっけ・・・?と思って論文を読みなおすとサラっとかいてあった・・・いや別の話か・・・いずれにせよコードみないとわからんだろこれ・・・。しかし moving average で内部状態が変化するような layer の微分可能性とかどうなってるんだろうか。まったくなぞ。
コアの実装はシンプルだけど、いずれにせよ自分のにわか TF 力では歯が立たず。まあそのうち出直します。
Optimization for Training Deep Models.
数学がきついかと思いきや、わりと大丈夫だった。なぜなら難しい話題は適当にはぐらかされているから・・・。そして前章につづき期待していたより面白かった。
まず deep network training の難しさは local minima ではないという主張が面白い。Local minima かどうかを調べる方法 (gradient の norm を求める) や、local minima が相対的には大した問題ではない話など。数学的に厳密的な議論ではないけれど、なるほどなーと思う。
各種アルゴリズムについては Coursera の授業ではさっぱりわけわからなかった RMSProp がすんなりわかってよかった。やはり cover-to-cover で順番に読んでいくの重要。つまみ食いだとわからない話もわかる。しかし learning rate の調整をこんなにがんばらないといけないのは大変だよな。
BFGS のような二回微分を使う方法たち。自分はこの手の方法は Tensorflow などの Ops が二回微分を定義しないと使えないからダメじゃんと思っていたがそれは誤解で、実際は近似的な手法だと知った。
一方でこの手の強力な optimization algorithms を使うより train しやすいモデルが重要だ、という警告は面白い。別の言い方をすると、NN を blackbox として捉える旧来の optimization より NN の構造を exploit する pre-training や skip layer connection の方が強力という話。当たり前といえば当たり前だけれど、abstraction の壁を破ってチューニングすると大きな成果がでる展開は好き。もっとやれと思う。そういう意味で後半にちらっとでてきたもののさっぱりわからなかった Batch normalization は要復習。
前章とあわせ、関数の形に関する議論や、ネットワークの中を gradient が propagate していく(そして vanish/explode しないよう工夫する)みたいな概念にちょっと慣れてきた気がする。
なんかすごいツールの話ではなく、画面の上に出せるアレ。
実際に遅さを調べる段になると結構良い。自分の場合、普段さわっていない画面の何かが遅いから直せをバグをよこされ、まずどのくらい遅いのかを調べるのに使った。Systrace の方が詳しいけれど、この on screen profiler にも良い所がある。リアルタイムで結果が見えるし、ずっと動かしっぱなしにできる。ダンプした結果をホスト側で見ないといけないし、一回あたり数秒しかトレースできない Systrace と比べ、探索的な調査に向いている。なんとなくアプリをつつきながらグラフを眺め、平均的な挙動のトレンドを眺めたり、スパイクの出るタイミングを探したりする。
件のバグはタッチイベントがくるたび全ての View が rebind されるというもので、この rendering profiler で眺めたら UI thread の負荷が一目でわかる異常を示していた。でもこれって肉眼で見てるだけだと案外気づかないのだよね。デバイスが速かったり自分の目が節穴だったりして。
表示されているバーのうち、寒色系の部分は UI thread, 暖色系の部分は Render thread での経過時間を示している。二つのスレッドの結果を一つのバーに押し込んでいいのか疑問だったが、コードをみると所定のチェックポイントでのクロックを記録し描画の際にチェックポイントの間隔を長さとして描いていた。つまり並列に動いたぶんは本筋の処理にマスクされ、バー表示には計上されない。正しい。
別の見方をすると、Render thread は UI thread で view tree の drawing traversal がおわるまで仕事ができない。その順序は直列化されている。当たり前だけど UI thread がさっさとdraw を終わらせないと Render thread を utilize できない。各スレッドが素朴に 16ms まるごと使えるわけではない.
Draw のおわった UI thread はもうそのフレームでやることがない。だとしたら Render thread に描画を切り出すのって微妙に無駄じゃね?そう思いつつアプリの Systrace を眺めていたら面白いことに気づいた: RecyclerView は draw 後にある UI Thread の空白時間を使い、先のフレームで描くことになるであろう View を前もってレイアウトしている (GapWorker.java など参照。) これなら次のフレームの view traversal でレイアウトを計算せずに済み、Render thread を待たせない。UI thread の時間を最大限ににつかっている。賢い。
必要な View を事前に予測できる RecyclerView ならではのテクニックだけれど、そもそも UI を jank-free にしたい場面の多くは RecyclerView 的なスクロールなので、この頑張りはまったく正しい。RecyclerView の評価があがった。
Rendering profiler を眺めていると、フレームの大半の時間は暖色系の render thread で使われいることがわかる。なにかと非難されがちな UI thread, 案外遅くない。とはいえ多くのアプリはぽろりぽろりとフレームを落とす。そしてフレームを落とす原因の多くは UI thread の spike にある。つまり UI thread には大体速いが時々遅い。
UI thread を spike される原因はアプリ次第だけれど、ありがちなのはどういうものだろう。
しょぼい理由: 本来バックグランドでできるものをさぼって UI thread でやっている。ちょっとしたサービスのメソッドを呼んだら実は遅かったとか、サーバからきた JSON をもとに view-model 的な UI 寄りのオブジェクトを作る部分が UI thread だったとか。特に API なりデータベースなりから帰ってきたデータがでかいと UI thread を spike させがち。
もうちょっと本質的に大変なもの: View の遅さ。Inflation や layout といった処理は基本的に off-thread にはできないので、たまに遅い。Recycler View みたいに必要な差分だけ処理するならまに合うけれど, たとえば ViewPager とか Drawer みたいに大量の View を一度に新しく表示しようすると、inflate/layout/draw にはどうしても時間がかかりがち。事前に inflate しておいたり、逆に最初は placeholder を出しておき後から段階的に中身を埋めていくなどの小細工が必要になる。が、めんどい。理想的にはがんばって view を flatten し絶対的な計算量を減らせるのが一番。でもそれは更に大変。
UI thread 以外での計算も影響する。Sync や fetch なんかが典型だけど、あとは GC もけっこう影響がある。Stop the world は随分少なくなった最近の Android GC だけれど、別スレッドで動く collector や finalizer みたいなやつらもけっこう CPU を使う。あとは他のアプリのサービスとか。
結局コアが 4 つとかしかないところで並列に動く計算がそれ以上あるとメモリアクセスやロックの競合みたいな細かい話をするまでもなく UI thread は遅くなる。そしてコア以上に仕事があることはぼちぼちある。なにしろ UI thread と render thread だけで 1.5 コアくらいつかっているから、他の仕事のための余裕それほど多くない。
Systrace はどの software thread がどの CPU で動いていたかを記録してくれる。CPU時間不足が一目でわかってよい。
Rendering profiler では、Render Thread の仕事を 1, Bitmap の upload, 2. Display list の traversal, 3. GPU の計算待ち の三段階に分類している。で、特別な場合を除くとだいたいは 2 が支配的。というか、UI thread を含めても 2 の display list traversal (と、それにともなう GL API 呼び出し) が一番遅い。バーのうち赤い部分。
伝統的な 3DCG の視点で見ると、これはちょっと面白い。GPU に計算をさせるというとき、3DCG だと vertex buffer とかに描画に必要なデータを詰めこんでまとめて GPU に送り、粗粒度で GPU に計算を任せる。テクスチャとかも atlas とかにまとめる。Android の render thread はそういうことはしない。というかまあ、できない。アプリの UI はバッチ描画向けに作られていないから。描画順序の reordering で状態の flush を最小化するような工夫はあるらしいけれど、基本的には毎フレームベタベタと描いていく。
Core Graphics みたいに描画結果をテクスチャとしてキャッシュすることもない。いちおう Surface を使えば似たようことができなくもないけれど、すくなくとも RecyclerView はそういう作りにはなってない。毎フレーム律儀に GL で順番にビューを描いて、それで 60fps を目指す。険しい道のり。現実的でもある。
Display list のトラバースが遅いのを見ると GPU 化も台無しじゃん、とか一瞬思ってしまうけれど、よく考えると描画を GPU に offload できたおかげで display list の遅さだけが残ったとも言える。そのうち Vulkan の command buffer を cache するとかいいはじめるとかっこいいんだけど、どうかねえ。
あわせてよみたい: Android Graphics Architecture
可処分時間が減った結果、英語訓練が蹴りだされてしまっている。
せめて iKnow と何らかの発声訓練(音読, shadowing とか)をしたいのだけれど、どちらもできていない。iKnow は晩飯の前後でなんとか隙を見つけてやる、という形で立て直しつつあるものの、発声がまだ。
発声は、できれば朝やりたい。訓練という以上に仕事前の準備運動みたいなものなので。でも朝はすでに目一杯なのだよなあ。弁当の準備やストレッチなど他の朝の作業にかぶせてみようかと思ったものの、うまくいかなかった。弁当につばをとばしそうだし、それ以上に発声訓練は「ながら」でできるほど負荷が低くない。
会社の昼休みとかはどうかと思うも、まず場所の確保が大変だし、場所があっても気が引けるなあ、脈絡ない音声を会社の中で発するというのは・・・。あとこれに限らず昼休みになんかやるというのはだいたいうまく行かないよね。社交もあるし。なお訓練とかするヒマあったら実践の機会を増やせば、みたいな意見は存じあげてますのでほっといてください。
実践といえば、新聞の購読をやめて以来それなりに実のある英文を読む機会がすっかりなくなってしまった。新聞記事は割と難しめの単語を使ってくることもあり、覚えた語彙を試すのには素晴らしい機会だったのだけれど。技術書とかは語彙がボトルネックにならないから読みの実践には向かないし、中身が難しいぶんチマチマ読むにも向かない。夜に 10-15 分くらいずつ読める、文章の洗練度以外で頭に負担のかからない、リーディング素材、なんかないかな。まあ本を読めという話な気はする。どういうジャンルの本が良いのだろうね。サイエンス系、ジコケーハツ系は技術書と同じ理由でダメ。小説?ノンフィクション?うーむ。
機会学習のラベル付きデータを主に扱う crowd sourcing の会社らしい。ゴールドラッシュのツルハシ売りみたいな商売で儲かりそうだなーと思ったがエンジニアリングの求人はなかった。薄利なのか・・・。顧客リストには大手テック企業が並んでいる。
ラベル付けを効率的にやるのはいうほど簡単でもなく、たとえば image segmentation とか手作業でやるのは地獄なので ML で支援したりするらしい。そしてツールの出来も重要だとか。この ML -> Crowd -> ML というパイプライン、なかなか未来というか狂ってるというか、あんまり参加したいパイプラインではないな。
Goodfellow 7.11 の (7.35) がなぜ ensemble が機能するかを説明している。要するにエラーの式の中に covariance が出てきてそれが (良い ensemble model では) 小さくなるから、という話をする。(e0+e1+e2)^2 を図に書いてみると、斜線でない部分の値が covariance の力で本来の面積より小さくなる。
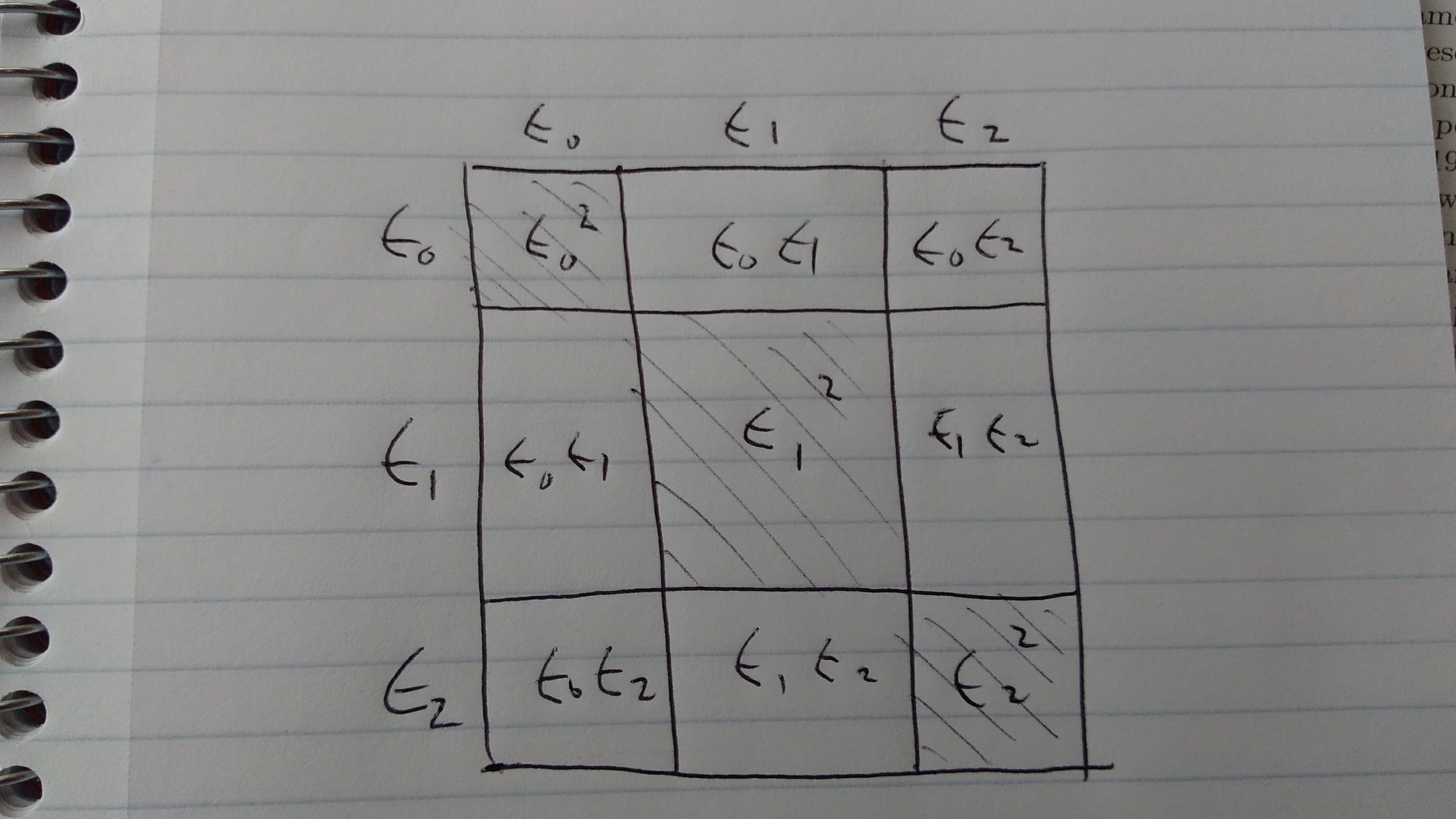
いまいち納得がいかなかったけれど、考えているうち個々の e が確率変数だから単純な実数のようには振る舞わない事実に段々と納得してきた。確率勉強しないとな・・・。
週に一章すすむのがせいぜいという悲しさよ・・・。
Regularization. 大して興味を持っていなかったのでぼんやり読んでいたら、思ったより面白かった。まず Dropout が丁寧に説明されている。TensorFlow 入門とかでやったときはこれは不思議なものだなーと天下り的に理解し、Coursra NN4ML の授業で少し理解できたところ、この章でもう一段理解が深まった。Dropout すごいね。計算量をケチれるだけでもすごいけれど、入力だけでなく様々な段階の representation にノイズを差し込めるというのも NN の性質をうまく活かしていてよい。
そのほか素人目には雑な思いつきにか見えない手法たちの理論的裏付けが軽く説明されているのもよかった。Early Stopping は L2 regularization の仲間だし、Data argumentation も adversarial training も tangent propagation だ、といわれるとなるほどと思う。まあ証明にはついてけないのだけれど、こういう雑にしか見えない方法もちゃんと reason されていることがわり deep learning も世間で言うほどデタラメカーゴカルトでもないと信頼が高まる。こういう demythification 体験は読書のやる気につながってよい。でも Manifold Hypothesis とかが完全に腑に落ちて身体的なレベルで理解できてないと、本当の意味でわかってるとは言えないなとも思う。
もし次のプロジェクトを探しているならコードベースの依存関係を整理して小さいモジュール (Maven 的な意味で) にわけてビルドを速くする仕事はどうかと TL がいう。人にいわれたことをやるのは基本的には嫌だけれど、これは動機を共有できる。今の spaghetti monolith を殺したい。
社内ではモジュールの単位として Java のパッケージをつかう流儀で、モジュール間に cirular dependency があってはいけない。なので適当に class file をパースして dependency graph を作り、circle を探しつつ殺していけば最初のステップとしては良い気がする。そこに ASM とかがある Java のエコシステムはさすがに成熟してるなと思う。
とはいえ Java でグラフいじりみたいなコードを書きたくないなーどうせ移行が済んだら捨てるコードだし手元で動かすだけだから Scala で書いてみるか・・・と久しぶりの Scala. そして file traversal の API をみたら Stream がつかわれている。それじゃと Java 8 にもちょっとだけ入門.
Kotlin をやってから Scala に来るとcollection まわりが混乱する. なんとなく List と書いてコンパイル通らねえーとおもったら java.util.List じゃなくて Scala の List だったとか、Stream も Scala の Stream と Java の Stream は別物とか。しらねー。Kotlin は自前の collection はわずかだし、あってもだいたい Java 互換なのでそういう混乱は少ないのだった。Scala は Scala native な API の上で暮らさないとイマイチだね。
とわいえ高階関数をギュっと凝縮して書けるところは Kotlin にはない Scala の良さで、このトラバースしてフィルタして変換して・・・みたいな仕事には向いている面もある。ASM をつなぐところから先は全部 Scala のコレクションで頑張れば良いのかもしれない。あと SBT は良いと思うのだよな。Gradle よりちょっと速い。IntelliJ ともうまくつながってる。あと Kotlin との比較はともかくさすがに Java よりはだいぶ良い。
しかし家に帰ってきて冷静になってみると、会社員としてこれほんとに Scala で書き続けてよいのだろうかと疑問が湧く。プロジェクトのレポジトリにはチェックインできないし、他の人に動かしてもらうのもだいぶかったるい。残念だけど Java で書きなおそうか、それともダンプする部分だけ Java で書いてその先は Python にしようか。調査が終わったら何らかの指標を日次で集めて dashboard にしたりしたいかもしれず、それには Python の方が都合よく思える。でも言語を跨ぐのはそれはそれでめんどくさい気もする。はー。Java 書きたくないなあ。
結局 Scala のまま続けている。データサイズが小さいので Stream とかいらねーな、ということで早めに Scala のコレクションに変換して作業。やーこの手の雑だけどロジックが微妙に複雑みたいな作業には便利だね Scala。まあまあ速いし。でも世の中の雑用は I/O bound な上にロジックより手前の細々したところが複雑なことが多いせいで出番がすくなくて残念・・・。
あと書き捨てスクリプトとして使うのに SBT は大げさすぎなので pip や gem みたいにグローバルにライブラリをつっこむオプションもほしいところ。まあ探せばあるんだろうけれど。
新しい Youtube のウェブサイトが Polymer ベースだと知る。自社ライブラリとはいえ、こんな重要かつ巨大なものに使ってもらえるとは。がんばったな中の人たち・・・。DevTools で element tree を inspect すると Atom で Custom Elements を見て以来の感動がある。
最近の JS フレームワーク戦争は React で決着がついたと理解しているけれども、Polymer も YouTube が使ってるとなれば打ち切られることはないだろうし GitHub も活況ぽいので、ニッチとして引き続き良くなっていって欲しいなと思うのだった。
社内求人を眺める。
別にすぐチームを移りたいわけではないけれど、あと一年たつと今のチームも三年。その頃には移れるようにしたい気がしている。よっぽど良い trajectory を引き当てているのでもない限り、同じところに長くいるのは良くないので。前の仕事は長くやりすぎた反省がある。
が、とくに移れそうなポジションが見当たらず消沈。社内のポジションたちは具体的な専門性が求められる上、勤務先の注力分野の移り変わりは速い。いま興味深いポジション(群)があって、じゃあそれに必要なテクノロジーを勉強しましょうといったところで一年たつと似たような仕事はなかったりする。まあ ML Researcher みたいなハイエンドなやつはしばらく活況だろうけれども...
基本的には、なんらかの興味ふかいポジションが生まれた瞬間にその requirements がそろっていないと厳しい。一年後、N 年後に仕事を変えられるよう、その時に必要なテクノロジーを見越して投機的に勉強しておく・・・のも難しい。そんな鼻が効けば苦労しない。
「ポジションがない」はいいすぎで、たとえば Android アプリ開発者のポジションとかはそこそこある。が、それは別にやりたくない。今と大差がないから。新し目のチームにいけばコードベースがモダンとか多少はいいこともあるだろうけれど、でもアプリ開発に変わりはない。定期的にチームを移りたいのは新しいことをやりたいからで、ちょっとマシな似た仕事をしても仕方ない。それなら今ある手元のコードをマシにするようがんばる方が良い。現状が絶望的にすごくダメなわけではないし、時間をかけて獲得した信頼みたいなものもある。そもそも今のチームはコード以外は割と好きだし。
時代が先に行ってしまい、できることとやりたいことがすっかり乖離してしまった。更に、やりたいことのうち「理屈の上ではよさそうな仕事」と「自分が興味や熱意をもてそうな仕事」も離れてしまった。これは「できる」と「やりたい」との乖離と対をなしている。自分が熱意をもってとりくみ身につけたテクノロジが obsolete になってしまい、自分のよくわかっていない何かをやる必要があるわけだから。なんとかして自分の関心を時代に合わせて書き換えないといけない。先のことを考えず楽しく働くだけでいいならずっとブラウザのコードでもいじってるわけで。
テクノロジーのキャッチアップをさぼった状態で人生の厳しい時期に踏み込んでしまった。その事実は今更そうそうひっくりかえせない。何らかの諦めが必要で、数年おきに新しいことをするのも諦めるものリストのひとつなのかもしれない。年数をあける、のはますますバーをあげるばかりだから、「新しいこと」の新しさを犠牲にするくらいのトレードオフを探ればいいのだろうか。
あとは社内社外によらず、求人情報を自分の勾配に使うのは churn が多すぎるなあ。リストを眺めては絶望するのを繰り返すと時間も精神力も磨耗するばかり。精神衛生を regulate する意味で一年くらいのしばらく求人閲覧はやめておく。求人よりもう少し一般的な流行り廃りを気にしつつ、自分の価値観や関心分野のアップデートを優先した方がよさそう。
子が熱を出したので欠勤。
今は休暇が余ってるから良いけれど、赤子が風邪を引きがちという事実を考えると Work From Home の準備を整えないといけないなあ。しかし家から働くにはアプリをビルドできる環境すなわち Macbook を持ち歩かないといけない。というかランニング通勤なので Macbook を持って走らないといけない。重い。
勤務先はそれなりにセキュリティの厳しいところなので、たぶん世の中の小さい会社よりはプログラマとして WFH する敷居は高い気がする。制度面では問題ないだけに惜しい。ミーティングとか VC できるからふつうにリモートで問題ないのに、コードが書けないとか台無しじゃん・・・。
ターミナルとかウェブで開発できる仕事ならまだなんとなかるけれど, Android Studio はさすがにリモートだと厳しい、気がする、が、諦める前に Chrome Remote Desktop は試してみるべきかもしれない。
仕事の quarterly だか bi-annually だかの performance review. クビにはならないが出世もしない、優良可の良みたいなスコア。おおむね期待通り。自分は今は仕事の自律性というか自分で決めて自分でやることに重みを置いているので、それだけ勝手にやっていて良ならいいんじゃねと思っている。
一人プロジェクトをやるには、本人の能力や嗜好だけでなくマネージャやチームとの相性も必要だと思う。自分はその点で運が良い。Performance review のミーティングで「人々がみんな新機能のために忙しく働いてるのに自分だけ違うことしてていいんですかねえ」とマネージャに尋ねてみる。「チーム全体と違うことをやってるからってそれが重要じゃないってわけじゃない」との答え。まったくその通りであるとはいえ、そういう価値観が共有されているのは助かる。チームの人々もそう思ってくれていると良いのだけれど。
チームとの相性という点では、チームの中に性能改善の得意な人が少ないのもよかった。これが性能重視なチームでインフラもそろっていて人々が日々ベンチマークやプロファイラに目を光らせていたりすると自分の出番がない。エンジニアリングが(相対的に)弱いチームなおかげで自分の立場がある、というのは皮肉な話だけれども、それが身の丈なのであった。
でもいざ育休が明けてさてなにをしようかと考えた時、意味のある一人プロジェクトを考える難しさに挫けそう。
リリースが近いこともあって、今は遅れ気味な隣の人の仕事を手伝っている。久しぶりに機能追加のコード書き。こういう、誰かの考えた機能を誰かの考えた締め切りにあわせ誰かのコードに書き足す、という感じで働くのはやだなあ・・・。と思ってしまった。前にも書いたけれど、こういう手伝いだと、プロジェクトにいまいちなところがあった時に腑に落ちにくくてフラストレーションが溜まる。惰性で手伝いの続きが回ってこないよう、さっさと自分のやることを考えなければ。挫けていた気分を立て直した。
一人プロジェクト、やることを決めるのが一番しんどい。そしてなにが合っても16時半に帰らなければいけないという時間制限もしんどい。はーなにしようかなあ・・・。