CS224n をやりはじめたのだけれど、最初の宿題から早くも挫折。むずかしす... 「Softmax/Word2vec の微分を求めましょう」や「NumPy で Word2vec のコードを書きましょう(穴埋め)」など。最初にみた授業は講義時間の半分くらいその証明に費やしており、かったりーとハナクソほじりながら見ていた。ごめんなさいとしかいいようがない。最初の方の簡単なやつだけやって、あとは降参。数式系はともかくコード課題が出来ないと自分の無能に打ちひしがれる。
授業はまあまあ面白いし参照されている論文も relevant ぽいので、落第しつつも今のところコンテンツは消化する予定。この授業をやっているだけで今年は終わってしまいそうだ...
宿題を本気で突破したいならビデオもぼんやり見るのではなく授業をうけるかのようにがっちりノートを取る必要があるのだろうなあ。 224n の前身 224d には lecture notes がある。231n にもある。224n にもつくってくれー。数式とかをさっと参照する方法がないと辛い。
次のビデオからはいちおうノート用紙を用意のうえ鑑賞します。はい。
それにしてもコンテンツの題材はともかくシステムとしての出来は Coursera の方が良いよなあ。 cs224n はビデオも一本が 80 分くらいあって集中力が保たないしそもそも一日では見終わらない。そして宿題も複数のビデオを見終えた後にドカっとやってくる。ビデオを小さく、宿題も細かく出してくれる Coursera の素晴らしさを思い知る。Hinton NN だって Coursera じゃないところで授業うけたら間違いなく瞬殺されてしまったよ。きっと。
まあ cs224n も utoronto も高い授業料を払って大学に通っている人々には TA などから手厚いサポートがあるのだろうけれど。
追記
せめて正解は覗いておこうとどこかの誰かが書いた宿題コードを見ていたら, "see note1 p12" とかかいてある。はて、とサイトをよく見ると・・・ノートあるじゃん!!! OMG!!! 今日はこれを読みます。はい。
自分が抱いている TensorFlow のメンタルモデルを書き下してみる。現時点での自分の理解を整理記録するのが目的なので、正しいことは期待していない。
TF はある種の言語処理系、インタプリタである。専用の文法はなく、プログラムは Python の DSL として与えられる。TF の Model はその TF 言語で書かれたプログラム。プログラムは Session を通じて実行できる。
プログラミング言語としてみた TF 言語の表現能力は高くない。たとえば関数とかは定義できない (ほんとに?)。再帰もない気がする(ほんとに?)。Ops と呼ばれるプリミティブを式として組み合わせて何かを計算するのがもっぱら。Ops はプリミティブなので TF 言語自体では定義できない。ただし C++ や Python で拡張することはできる。SQL の UDF を定義するようなもの。まあ SQL の UDF は SQL で定義できるのかもしれないが。誰得。
TF 言語はプログラム内の式の微分を計算できる。それが典型的なプログラミング言語と大きく異なる。この機能を実現するため、全ての Ops は自分の微分を定義しないといけない。(たぶん全てではない。微分要不要の境目はなに?)
とはいえたとえば BUGS のような特殊なドメイン言語は微分じゃないけど似たような特別な性質を持っているので、すごく珍しい話ではない。
TF 言語はまた、並列化や分散化、永続化などを組み込みでサポートしている。これは Python をネイティブ言語とする PyTorch などとは異なるところ。DSL として自分の言語を持った強みと言える。かわりに分岐とかループとかを書くのがめんどいのが欠点。
DSL として言語/モデルをわけておく別の利点は、Python のレイヤでメタプログラミング的なことがやりやすいこと。たとえば Model/Variable の save とかで保存したいノードを選ぶ、みたいなコードを普通にかける。他の言語だと compiler plugin とか macro とか reflection になりがちな部分が普通に触れる。一方で普段から reflection だけでコードを書かされているだけなのでは、というツッコミはありうる。Lisper と Haskeller だけがこのぎこちなさをディスって良い。
と書き出してみると、主張の正しさも何も肝心なところはまったく理解してないと思い至る。
たとえば TF 言語処理系だというなら、そのインタプリタはどのように実装されているのか。プリミティブのうち、本当にプリミティブなものは何で、どこからが sugar なのか。たとえば Variable というのはどのくらい特別な存在なのか。Optimizer はどのように動くのか。Saver で保存される Variables と GraphDef はどんな関係があるのか。などなど・・・。
そのうちコードでも読んだほうがいいんだろうけど、まあ当面は基礎を地道にやります。はい。
Learning TensorFlow, データパイプラインの章は「このへんの API は変わりそうだけど一応紹介しとくね」と書いてあり、案の定 1.2 から新たに Dataset がはいった。これが新しい標準になるということらしいので、 Learning TF のデータ IO の章は飛ばし Dataset API を軽く試してみる。まあまあ良さそう。
どちらかというといまいちなのは推薦ファイルフォーマットとされている TFRecord および tf.train.Example. まあ TFRecord はいい。しかしこの Example, ひどくね? Proto むきだしで、これを Tensor と相互変換する方法がロクにない。書き込みが多少面倒なのは我慢するけれども、読む方はもっとスカっと読ませてくれよ・・・・。
こうした推薦フォーマット/API にのっとるとマルチスレッディングの恩恵が受けられるというけれど Proto のパースと整形のために tf.py_func を挟まざるを得ず、これほんとに off-loading されるのかね。理論上はたとえばグラフの評価は完全に C++ だからそのあいだ GIL を手放していれば別スレッドで Python コードが動けるわけだけれども、ちゃんとそのへんがんばってるの?なぞ。
適当な Proto じゃなくふつうに HDF5 とかをサポートして、ファイルから Tensor へ直行できるようにしてほしいなあ。
Wikipedia, Paper.
機械翻訳のスコア付け方法。スコアは 0 から 1 の間になるといっているけれど、 NMT の論文たちはもっと謎の数字 (30 とか) になっている。なんなの... よくベンチマークにでてくる WMT のサイトをみると NIST BLEU Scorer を使えとかいてある。これが謎の数字の source of truth なのだろうか。そして一部の翻訳データは Yandex など企業が提供しているのだね。日本の景気のいい会社も J-E のデータを提供して researcher が日本語でテストできるようにしてほしいもんです. French だの German だの今時どうでもいいじゃん。Japanese もどうでもいいっちゃいいけど自分的には重要。
BLEU 自体は ngram を使うなどよく考えられた指標だなと思いました。
モデル定義 DSL と評価結果が混ざる問題は、今のところモデル定義を適当なクラスに押し込んでお茶を濁している。
class Model(object):
def __init__(self):
self.graph = tf.Graph()
with self.graph.as_default():
self.x = tf.placeholder(tf.float32, [None, 784], name='x')
self.W = tf.Variable(tf.zeros([784, 10]), name='W')
self.y_true = tf.placeholder(tf.float32, [None, 10])
self.y_pred = tf.matmul(self.x, self.W)
self.loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=self.y_pred, labels=self.y_true))
self.train = tf.train.GradientDescentOptimizer(tf.constant(dtype=tf.float32, value=0.5, name='weight')).minimize(self.loss)
self.accuracy = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(self.y_true, 1), tf.argmax(self.y_pred, 1)), tf.float32))フラットに置いておくよりはマシなのでこうしているけど、もうちょっとマシな方法ないのかなーと思ってしまう。クラスでなく関数にすると self がきえてすっきりする一方、公開したい tensor に名前をつけるのがめんどくさくなる。
今あまり追求しても overkill な気がするし独自の流儀を開発するのもやだから、誰かなんとかしておくれ。それなりにまとまった規模のある TF プロジェクトを覗いてみるべきなのかもなあ。
Tensorboard, サンプルはみな重みを観測するばかりだけれど、Backprop 理解しろ記事を読んで以来 gradient を監視したほうが良いのではと思っていた。でも gradients って TF の外側から観測できるものなのだろうか。
とおもって調べたら tf.gradients という API を使えばいいらしい。これが TF autograd の入り口なのだね。そしてこの周辺の API を使えば Python だけで optimizer も書けそう(書かないけど)。TF, 案外 extensible につくられていた。見くびっていて悪かった。
Tensorboard で graidient を観測するサンプルもあった。
写経つづき。
RNN/LSTM のサンプルを動かす・・・と、CPU が振りきらない。最大 400% のところ 250% とか。CNN では振り切っていた。いくら toy program で dimention が小さいとはいえ、Laptop の CPU も振りきれないとはだいじょうぶなのか RNN. seq2seq も LSTM を stack してレイヤごとに GPU を割り振る。無理やり並列度を上げてる感じ。GEMM とかはある程度並列化できるのだろうけれど。カーネル単位でじゃんじゃん並列化できる CNN と比べると辛い。
もっとも逆に言うと higepon_bot みたいのをトレーニングするのに速い計算機を借りる必要がない(借りても無駄)ということだから、趣味プログラマ的には良いジャンルなのかもしれないなあ。
去年 deep learning とやらを勉強しようと思いたって最初にたてた目標は "word2vec を理解する" だった。適当な目標にむかって逆算しながら入門する方が効率が良いと思ってたてたマイルストンだけど、いま思うと筋が悪かった。はさておき、そのときは細々した資料を読んだ結果テキストデータを通じ distributed representation を学習できるという A Neural Probabilistic Language Model の主張したいことはわかるようになったものの、アーキテクチャとかはわかららずじまい。挫折して逆算は諦め、普通に入門することにした。
時は流れ Learning TF 本をはじめ各種 TF 入門に word2vec が出てくる昨今。しかし実際にコードを写経してみるといまいちわからない。何がわからないのか、いまいちど word2vec の paper を読みなおしてみる・・・と、やっぱわからん。
さすがに一年前よりは理解が進んでいるけれど、データや語彙のサイズに依存しない probability (loss) の計算方法という肝心な部分がよくわからない。
TF tutorial 群では tf.nn.nce_loss という関数を使っている。ということで次に Learning word embeddings efficiently with noise-contrastive estimation を読む。が、わかんねー。Linear regression を解いてあげればいいんだよというけれど、肝心なところがめちゃ確率変数の世界。Noise Contrastive Estiamtion の出典はこれだということでチラ見したら理解するのは無理げな雰囲気。撤収。Word2vec のような一見基本的なものがこんなに確率変数ばりばりの方法に依存していたとは・・・。
nce_loss のAPIからリンクされている資料によると、NCE やオリジナルの word2vec がつかっている negative sampling などは candidate sampling とよばれる手法のひとつらしい。割と出番がありそうだけれど理解できてない。つらし。仕組みはともかく意図はわかるので blackbox として使うのだろうな。
via Neural Architecture Search with Reinforcement Learning
話題になっている論文を読んで全然わからず撃墜されようシリーズ。
これはまあ表題にあるような話で、具体的には LSTM で CNN や RNN のアーキテクチャを生成し、その性能を実際に train して求めては reinforcement leraning で探索する、というものらしい。よりまともな説明は Research Blog: Using Machine Learning to Explore Neural Network Architecture などを見ると良い。
NN で RNN/CNN のアーキテクチャを探索(生成)するというのが面白いところなのだと思う。うまい具合に解空間を絞っておいてあげないと探索しきれないので、そのへんのさじ加減が妙。
それはさておき自分はそもそも reinforcement learning が全然わかってない。gradient が計算できなくても "policy gradient" というのが計算できればよい、らしいが、なんだそりゃ。総当りや greedy とも違うのだろうし、なんだかまったく謎。Reinforcement learning なんてロボットとかやってる人だけのニッチかと思っていたら、こうして汎用的な目的でも使えるのだなあ。きっとそのうち勉強しないといけないものなのでしょう。そんなもののリストはひたすら伸びていくばかり・・・。
あとぎょっとしたのはトレーニングに 600 GPU も使っているというところ。NN 関係、分散できそうで案外できないように見えていたけれど、そんなにスケールできるとなるといよいよでかい企業の独擅場になってしまいそう。ちょっと前に FAIR に CNN をガっと 200 GPU くらい使って並列化する話があったのを思い出す。まあ独占的にでかいデータセットを使う話ではなくあくまでアルゴリズムの範疇なので、外野でも再現性はあるといえばある。AWS でやるとか。しかし金のかかる世界であることには違いない。
続編にあたる [1707.07012v1] Learning Transferable Architectures for Scalable Image Recognition では、前の論文で発見したアーキテクチャ(を改良したもの)を積み重ねて使ったら探索に使った以外の、より大きなのデータセットでもいい結果がでたよ、という話。Neural Search でみつけた architecture が transferable なのだとしたら(そして transferable ってのは割と信憑性あるよね。結局実践の場ではどこかの researchers が手動で発見し論文に書いた architecture を再利用しているわけだから。) もう国家予算で 10000GPU くらいかき集めて最強の architecture でも探せばいいのでは、という気になってくる。天文学者が望遠鏡つくるみたいな・・・。
と、わからないなりに SF ぽさを楽しめる部分もあるね、NN 論文。楽しいという以上の効能はさておき。
本の写経をちまちまと進めている。意外とはかどらない。TF, 書いてみると事実上新しいプログラミング言語を覚えるのに近い。しかも言語の出来はあんましよくない (Python の DSL だから。) そして Mathy. なので写経といえどもけっこうもたつく。
そしてトレーニングが遅い!CNN で CIFAR10 してみよう、みたいなやつが手元の XPS13 だと普通に 15 分くらいかかる。15 分、たぶん界隈的には一瞬なんだろうけど、一日一時間しかない人にとっては割とつらい。トレーニング中はほっといて先の方の写経を進めるなど並列化しているけれども、限度があるなあ。この本で一番重そうな model はこの CNN なので写経をしている間は我慢すればいいが、もうちょっと込み入ったものを扱いだしたらラップトップで作業は辛い気がする。ラップトップ、遅いだけでなく画面を閉じると止まってしまうからバックグランドで動かしておくのも難しいし。クラウド利用を再開しないとなあ・・・。
少し前に Benchmarking TensorFlow on Cloud CPUs という記事があって、この人によると価格性能比がいいのは GPU ではなく CPU らしい。まあそうでしょう。それより興味深いのは、TensorFlow を PIP レポジトリ経由でインストールするかわりにコンパイラの最適化オプションを指定し自分でビルドすると CPU なら倍近く速くなるという。なんだそりゃ・・・金をケチるためにはビルドしたほうがいいが、環境構築にビルドを混ぜたくない。なやまし。
GCE の pricing を調べる。n1-highcpu-8 で考えてみる。月 $200. Preemptive Instance が使えると安いけれど、それだと boot disk が消えてしまうとかでややめんどくさい。一方で月に $200 ドルも払いたくないから、この高いインスタンスを必要なときだけ起動するみたいな使い方が良かろう。
必要な準備はなにか。最低限の provisioning script は前に買いたやつがあるから、あとはトレーニングが終わったら shutdown するスクリプトを書けばそれでいいかな。コード書くのはしばらくは Jupyter Lab で我慢しとけばいいでしょう。
ま、実際にやるのは写経活動がおわったあとなので細かいこともあとで考えます。
完全な脱線として手元のラップトップを速く出来ないか物色してみる。今の XPS 13 は i5 2.3-2.8GHz. 2 core (+HT). Macbook Pro にすると i7 2.8-3.8 GHz 2 core とか 3.1-4.1 GHz 4 core とかがある。そしてこの速くて高いやつは $3000 くらいする。 XPS13 の倍以上の値段だけど、性能も倍か。ちなみに XPS15 は同じ性能で $2100 くらい。しかも NVIDIA の GPU がついてくる。しかし Linux を動かすのは大変そうなのだった・・・。
Dell のコンシューマ向けのやる気の無さからして XPS15 Developer Edition が出る日は来ないだろうし、やっぱりクラウド生活に体を慣らす方が時代に即してる、気がする。
Learning Tensorflow の写経を始めた。色々あそんでみるにあたり TF スキルが bottleneck に思えてきたため。頭が元気な朝の時間を写経のような低負荷な行いに使ってしまっていいのか不安だったけれどやってみると TF コード書きはまあまあ mind melding で悪くなかった。後半の分散化とか high-level API とかは写経に値するか微妙というかたぶんいらないので、途中までやって切り上げる予定。
以下 TF コード素人感想。というか不満点。こうした不満が大局的に的を射ているとは思っていないけれど、まあ入門時の気分を書き留めておくとあとから見て面白いかもな、ということで。
よいところ:
- Computation graph をつくって評価するというアプローチ自体はまともだなと思う。というか他のデザインがすぐには思いつかない。 Torch とかは違うというけれど。
- グラフ構築の API にきちんと operator overload をつかい、かつ numpy 互換ぽくしたのは偉かった気がする。
不満:
- 計算グラフの変数 (tf.Tensor) と評価後の値の変数 (numpy array) がまざりがちで辛い。この2つはある種の鏡像なのだから、その対称性や、逆に生きている世界が別である事実はデザインの上で強調されるべきだったと思う。
- Python の with が過剰。 Device とか引数にわたせばよくね?同じことは Graph にも言える。特に辛いのが Session の closer に with をつかっているところ。Session を使ったコードブロックは膨らみがちなため、インデントされたコードの範囲がどんどんでかくなっていく。これが Jupyter だと辛い。まあ Jupyter では InteractiveSession を使えということなのかもしれないが。あと with に頼らざるをえないのは Python に無名関数やブロック記法がないせいなので TF のせいじゃなくて Python のせい、とも言える。ここでブロックが使えたら Tensor と Numpy がまざる問題もだいぶ軽減されたのにね...
- Session.run() の feed_dict が global() でひっこぬく前提の作りになっている。変数名と Tensor の 名前が混じり合って辛い。これも Python 側での名前と Tensor name を一致させる努力をしてほしかった。Graph の __setattr__/__getattr__ を使うとかさ。やりようはあるじゃん?
TF は割と lower-layer な抽象のはずなのに中途半端に API usability をがんばっているのが違和感なのかもしれない。最終的には何らかの higher-level API を使いましょう、という話なのだろうけれど、たとえば Keras みたいにガッチリ下のレイヤを隠してしまうのが常に良いのかはわからない。むしろ best practice を encourage するような薄い層をかぶせるくらいでいい気もする。
あとどこまで Jupyter Lab(Notebook) で書いてどこから .py を書くべきなのかもわからない。training を Jupyter Lab から実行するのはなんとなく脆弱でイマイチにおもえる。が、一方でモデルをつくったりデータを除いたりするのは対話的環境の方が嬉しい気もする。データ整形と可視化だけで機械学習のない Data science ならまあまあ全部 Notebook でも良いと思うんだけど。このへん世間の人がどうしているのか知りたい。
Kullback–Leibler divergence. これがさっぱりわからず喉につかえていたため、 Amazon でみつくろった易しい情報理論の本を読んでいた: Information Theory: A Tutorial Introduction. 200 ページの薄い本。150 ページあたりでようやく K-L Divergence 登場。
K-L Divergence はこんなかたち...といってもこのブログは数式をつかえないため latex-like にかくと...
D_{KL}(P(X), Q(X)) = \int_{x} p(x) log \frac{p(x)}{q(x)} dxこれ以前みたときはさっぱりわからんかったけど、entropy を復習してからみるとなんとなく親しみのある形をしている。(そしてむかしむかし卒業論文とか書いてた頃はこの表記を脳内でレンダリングできたはずだが、今みるとぜんぜん読めませぬ。これは quicklatex.com で確認しつつ書いてます。)
これをちょっと変形すると腑に落ちやすくなる。
D_{KL}(P(X), Q(X)) =
\int_{x} p(x) log \frac{1}{q(x)} dx
- \int_{x} p(x) log \frac{1}{p(x)} dxひとつ目の項が P と Q の cross entropy, 2つめの項が P の entropy になる。 つまり cross entropy が単一の entropy よりどれだけ大きいかの指標が K-L Divergence.
D_{KL}(P(X), Q(X)) = H(P, Q) - H(P)なぜ cross entropy がこの形なのか(とくになぜ非対称なのか)は釈然としていないけれど、一方で Q = P のとき最小になる点を鑑みると有用性はわかる。そして NN とかの loss function だと P は training data で固定だから K-L Divergence を最小化するには cross entropy を最小化すればいい、というのもわかる。
というかんじで、完全に腑に落ちていないとはいえもともとは cross entropy の式の根拠がさっぱりわかっていなかったのに比べると表面的にせよ理解は進んだ。そして大した話ではないこともわかった。一方で entropy はけっこう機械学習っぽいこともわかった。150 ページを費やして得られる知識としては満足。せっかくなので残り 50 ページくらいもいちおう読む予定。
Deep Learning 本, 最後の 3 章は挫折。理由を考えるに、自分は Structure Probabilistic Modeling がわかってないのでその知識を前提に話をされてもわからん、ということだと思う。16 章でちらっと説明があるわけだけれど、こんな駆け足でわかるなら苦労しないです・・・
20 章 Deep Generating Models をわからないなりに冷やかして把握したこととして、generative models には undirected graph に基づくものすなわち RBM/DBM などと、directed graph にもとづくものすなわち GAN とか VAE とかがある。そして RBM 勢は世間のニュースを観ている限りいまいち盛り上がってない。ので undirected graph ベースの structured modeling はがんばって勉強しなくても当面はいいのではなかろうか。
一方で今をときめく GAN とかは directed graph ベースのモデルだとされており、つまり Bayes net とか標準的な PGM の延長にあるっぽい。したがって graphical model 自体は勉強しないとダメそう。GAN や VAE が実際に graphical model と言えるのかはよくわからないけれど、結局 generative models は確率変数になんかする話であり、確率ベースの方法論である PGM にはそのための道具立てが揃っている、ということなのだろうなあ。きっと。Edward みたいのもあることだし、NN と PGM は最終的には両方やんないとダメなのでしょう・・・。
本全体の感想。なかなかよかった。特に Part 2 の実践編がよかった。NN の基礎的かつ理論的な部分ではだいぶ理解が進んだと思う。Part 3 は自分にはまだ難しすぎたけれど、それでも representation learning の章は面白かった。目次を除くと 700 ページくらいのわりかし薄い本な点も助けになった気がする。これ以上厚いと辛いだろうね。
一方で薄いせいではしょられている部分も多いから、二版が出るなら間違いなく厚まりそう。だからこういう本は薄い版のうちから読むのがお得と RTR (from 500 pages at 1st ed. to 1000 pages at 3rd ed.) から学んだ。まあ改版しなそうな予感もあるけれど。このゴールドラッシュの最中によく書いたよねこの本。エライ。
このあとどうしましょう。
まずはいくつか復習したいことなどが溜まってきたので、そのために必要なものを読む予定。これはすぐおわる(希望的観測)。
あといいかげんコードを書きたい。TensorFlow, 公式ドキュメントがやや不親切で再挑戦は気が重いなあ・・・とおもいつつウェブを物色していたら O'Reilly から Learning TensorFlow という本がベータ版として出版されかかっており、ちらっと中身をみたかんじ自分には割と良さそう。機械学習とは・・・とかいう話をすっとばして TF の説明だけしている。おかげで薄い。これを読もうかな。Hands-On Machine Learning with Scikit-Learn and TensorFlow も Amazon のレビューを見る限り良さそうだけれど、自分は Scikit-Learn 成分は摂取済みなのだった。
そのあとは cs231n なり cs224n なりで画像処理なり自然言語処理との組み合わせを勉強したい気もするけれど、そんな気力が湧くかは不明。ひげぽん氏みたいに自分でデータを集めてなんかやるのも楽しそうだし。ぬるく TF 入門を済ませてから考えることにする。
Generative Models の勉強もそのうち再挑戦したいけれど、しばらくは放置かな。確率や PGM など generative models の前に勉強しないといけないことが多く、数式をかき分け厚い教科書たちを読み進める気力が湧くまでは無理。しかもそれらを読んでる間はほとんど手を動かせない。まあ generative models がわからなくてもできることは色々あるでしょう、きっと。
ところで generative models はどうやって勉強すればいいのかとウェブを冷やかしていたらみつけた U. Tronto の授業、シラバスに「最後のプロジェクトは NIPS に論文書きます(誇張)」とか書いてあってフいた。さすが AI のメッカはちがうな。
Monte Carlo Methods.
だいたいが、むかし途中まで読んで挫けた Doing Bayesian Data Analysis で勉強した範囲の話だった。Figure 17.2 の説明がおかしいな、とおもったら誤植だったらしくウェブ版では直っている。
Gibbs Sampling は追加でもうちょっとなんか読んでもいい気がする。Wikipedia とか。ただ究極的には stochastic process のようなものを理解しないと internalize できないだろうな。
Structured Probabilistic Models for Deep Learning.
いよいよサーベイみたいなかんじでささっと済ましてくるなあ。抽象的かつ概要的な話が多く雲をつかむような気分・・・。
Variational inference, D-separation, structure learning などなど新しくて難しい概念をバンバンつっこんでくるが全然 connecting dots されない。この先の章で使うらしいけれど、使われると死ぬ気がする。
最後にでてきた RBM は NN4ML でやったおかげでなんとなくわかった。
そろそろわからなくなりそうという不安を抱え続け、しかし概要的な話ばかりで決定的にわからない瞬間に出会わないまま 16 章も終了。いまいち張り合いがない。
RBM, 世の中ではほんとにつかってんのかなとライブラリを探したら sklearn に入っていた。がしかし、こういう切り口では使わないではなかろうか。もうちょっと stack とかしたいんじゃないの?全然 modularity ないよねこれ。
ちょっとぐぐると TF で RBM したよ、みたいなサンプルがちょこちょこある。そっちが正しいアプローチなきがする。自分で書いて、Optimization だけ TF に任せる的な。
Representation Learning
すっかり論文紹介といった風ではあるが、この章は面白かった。Deep Learning ぽい。Unsupervised Pretraining, Transfer Learning, Zero-shot learning, Distributed Representation, etc. ここでの議論にでてくるから事前に Autoencoder の章があったのか。あとは望ましい representation を learn させるための手法としてついにちらっと GAN が出てきて盛り上がるなど。
ただほんとに論文紹介なので、少しぐらいは読まないとなあという気がしてくる。特に zero-shot learning は話として面白いから少しはなんか読んでも良さそう。Google Translate の zero-shot training の話 はその仲間に数えていいのかなあ。ちらっと読むと、sequence の先頭にlanguage tag をつけたらあとはよろしく動いてくれたよ、とか書いてあるけどそんな単純な話じゃないよねたぶん。一方でざっとウェブを眺めるとだいぶ色々あってたじろく。
章の最後には「望ましい特徴量の性質」のようなものがリストされている。これはなんとなく「良いコードの性質」みたいな議論と似た雰囲気がある。素人としてはなるほどそうですか・・・とあまりピンとこないけど、経験を積んだ ML エンジニアは頷く感じなのだろうなー。頷く感じになれる日はいつか来るのだろうか。
Autoencoders.
Denoising と Sparse はわかったが Stochastic というのがわからん。そして参考文献もない・・・。Contractive もいまいちわからん。そして難しい割に盛り上がらないなあ Autoencoder. 使いみちも今や可視化くらいしかないというし。まあ NN4ML にもでてきた Semantic Hashing は面白い気もする。実用的にどうこういうよりは、non-linear な dimensionality reduction のわかりやすい例として教養として知っておきなさいね、ということなのかもしれない。
Keras のサイトにある autoencoder を作ろうという記事も、「最近は特に使いみちないけど授業によくでてくるせいで皆作りたがるからサンプル載せとくよ」みたいなことが書いてあって見も蓋もないのだった。
Part3 は詳しい中身には立ち入らず論文を紹介してくかんじになってきた。うーむ・・・。しかしぜんぶ理解しようと論文を読んでいるといつまでたっても読み終えられない。わからん、とかいいながら前に進みます。
Goodfellow Chapter 12 の復習。
まず [1] を読む。けっこうよくかけていたけれど、Encoder-Decoder の理解が怪しい気がしたため続けて [2] を読んだ。すると理解が怪しかったのは Neural Machine Translation や Statistical Machine Translation それ自体だったことに気づく。Phrase based SMT framework とかいわれてもわからん。しかし深入りするとキリがなさそうなので今は撤退。Encoder-Decoder に attention の context をつかうモデルについてはわかったのでよしとする。
ついでに Encoder-Decoder の同義語ぽくつかわれる Sequence-to-Sequence もチラ見しておこうと [3] を読んだ・・・が不親切すぎ!Deep LSTM ですかそうですか・・・というかんじだった。その点 [1] は Appendix にモデルが書き下してあってすばらしい。やはり企業の研究者よりアカデミアの方が論文さぼらなくてよいな。Bengio 先生はテックカンパニーとかに浮気せず世界のために丁寧な論文を書き続けて欲しいもんです。教科書も。
関連のある冷やかしでながめた Distill の [4] は attention の可視化がよかった。あと画像にも attention を使う話があると知った。
Attention という仕組みの素人感想。
Encoder-Decoder の自然な拡張に見える。というかもともと Encoder-Decoder が variable length の text を fixed dimension の vector に畳み込むという無茶をしていたわけで、無茶すぎたのをちょっと反省したらこうなったみたいなかんじ。ただ attention の割り振りを学習できるという発見はよい。この「パラメタは何でも学習しちゃおうぜ」という態度をネイティブに理解したいもんです。
Linear Factor Models.
突然難しくなった...
PCA みたいに feature extraction をするモデルのうち linear なものたちとして Independent Component Analysis, Slow Feature Analysis, Sparse Coding を紹介する。わからん。ICA は [1404.2986] A Tutorial on Independent Component Analysis でそもそもどういう話なのかを学び、ML 的文脈での解釈は Ng 師匠の notes で理解(師事してません)。 Sparse Coding は全然わからんけれど、あまり流行ってないといことなのでサボって無視。
こういう unsupervised な feature extraction はある種の generative model と解釈することができる。なぜなら extract した feature を model が想定する probability distribution から draw した sample で重み付けして足し合わせれば data を generate できるから。
こうした素朴(=Linear)な generative モデルから話を始めつつ、だんだんと洗練された手法へと話を進め、最終的には GAN にたどり着ける!はずだ!と信じて、わからないなりに読み進めてる。しかし先行きだいぶ不安。
なお ICA は sk-learn に実装が入っており、普通に便利げ。
Chapter 11 は Practical Methodology. Hyperparameter のチューニングからデバッグまで、短いし math もないけど良い章だった。ここに載ってるデバッグ手法を使いこなせるようになりたいもんです。
ただデバッグして hyperparameter tuning してそれでも結果が出なかったら practitioner にできることはありませんそこからは researcher の仕事です、みたいな言い分にやや萎える。わかってんだけどさー。
Chapter 12 は Applications. GPU, 分散処理, 画像処理, 自然言語処理, Recommendation....って盛り込み過ぎ. 書くトピックごとにどんな成果がでているかを紹介しつつ論文のリンクだけあるかんじ. 特に自然言語処理の章は全然わからんかった. 著者が他と違うんじゃね, という気がする. 知りたかったの attention mechanism についても結局よくわからなかったので要復習.
これで Part 2. Deep Networks: Modern Practices が終わった。もともとはここで切り上げる予定だったけれど、Part 3 も読みたくなってきたなあ。NN4ML のときにつまみ読みした感じだと math が難しすぎて挫折しそうだけれども、自分のわかってない限界を知るために読んでおきたい. くじけたら終了ということで.
引き続き読書に時間を割くということは、TensorFlow とかで実際にコードを書くのはまたしばらく(数カ月)お預けということでもある. ここで両方できない現状にはまったくがっかりする. でもそれが現実なのだった. Sigh. でもなんとなく続きを読んだほうがいい気がしているのです.
Sequence Modeling: Recurrentand Recursive Nets.
それなりに面白かった。Sequence-to-Sequence とかもでてきて、おおコレが話にきいていたアレか、と思うなど。
CNN も RNN もなんとかして parameter sharing をしつつ構造に関する prior knowledge をネットワークに埋め込もうとしているという点が腑に落ちたのはこの本を読んで良かったところだと思う。系統だった理解というやつ。のはず。
RNN, 前にやった時は結局どうやってデータを食わすのかよくわからず frustration が溜まったけれど、その後 Keras や TF のサンプルを眺めてデータは適当にぶったぎって固定長(未満)にそろえてつっこむ、ということを理解して以来 demythify された。そういう practical matter は理論的な本でも一応説明してほしいよなあ。
そのほか:
- Attention mechanism については 12 章までお預けだそう。
- なぜ RNN は ReLU でなく tanh なのかなぞ。(Quoraに同じ質疑応答あり)
- LTSM, Leaky Unit とかいって NN の非線形性を捨て線形な成分を混ぜて記憶とか言い張っているが、なんでそれでうまくいくのかなぞ。
- 最後の方にでてきた Neural Turing Machine の話はさっぱりわからず。要復習。Arxiv, 解説, 解説.
Packt, Amazon, Play.
Scikit-learn の使い方が知りたくて読んだ。TensorFlow は cross validation とかを手伝ってくれないので別の道具がほしかったのと、 Keras が scikit learn 互換だと何かで読んたため。
Scikit-learn を知るには良かった。知りたかったこと (Pipeline の使い方や GridSearch などの話題) がきちんとカバーされていた。コードは割とちゃんとしていると思う。著者は scikit-learn にちょこっとパッチを書いたりもしているらしい。
Machine learning 自体の学習にはいまいち。アルゴリズムや数式の説明の仕方がよくないと思う。知ってる人の復習にしかならない。アルゴリズムの説明は飛ばし読み。そのほか Web アプリを作りましょう、みたいな話も飛ばし読み。最後にでてくる NN の話はスキップ。
Coursera ML の後すぐに読めばよかったと今更ながら思った。 Ensemble 系以外はだいたい同じ話題を扱っている。これを読んでから Kaggle をやっていたらもうちょっと手を動かせたかもしれない。
そのほか。
Matplotlib 習熟の必要性を感じた。今のところ自分は Pandas の DataFrame.plot() でなんとか可視化をやりすごして来たけれど、それより numpy の array をズバっと描けるようになった方が柔軟で便利そうだと文中に登場する数々の matplotlib チャートたちをみて思った。
NN で扱うようなメディアや非構造データ自体を plot することはあまりなさそうだけれど、loss の変化とか gradient の norm とか plot したいものはなにかとある。Tensorboard でもいいのかもしれないけど、記録をとるには Jupyter に埋め込める Matplotlib が必要そう。どうやって練習しようかね。この本のサンプルコードを写経でもすべきか・・・。
Scikit-learn. 一通り色々実装されてるのはいいんだけど、ほんとに NN と一緒に使えるのだろうか。なにかとデータを全部メモリに乗せたがるし、トレーニング結果の check-pointing もなさそうだし、いまいち頼りない感じがする。でもみんなこれ使ってるんだよね?なぞ。
I/O の talk より: Open Source TensorFlow Models.
TensorFlow の人たちが公開している pre-trained なモデルを使って面白いことをしようという話。その中でも CNN の pre-trained model のうち最後のほうのレイヤだけを捨てて自分のデータセットでトレーニングし直すテクニックが面白かった。CS231N の lecture notes に同じ話題を扱った節がある。TensorFlow にもサンプルと解説が入っている。有名な話っぽい。
Goodfellow 本でもちらほら pre-training を議論するものの、それらは大体過去の話として扱われている。特に CNN の章には最近はぜんぶ train するのが主流と書いてある。たぶん state-of-the-art の結果を狙うならそれで正しいのだろうだけれど、金もデータもなく他人の成果にあやかりたい庶民の観点だと pre-trained なモデルを使い回せるならそれに越したことはない。
Transfer Learning, もっと cutting edge で難しい話題なのかと思っていた。でもこの例に限るとなかなかわかりやすいし実用的だね。
TensorFlow にもぽつぽつと pre-trained model はあるものの、この点 Caffe/Caffe2 は Model Zoo というのを保守していてえらい。NN のフレームワークとしては使えるモデルをいっぱい持っている方が良いと思うので TF にも見習って欲しいなあ。モデル欲しさにみんな Caffe 使うようになったらどうすんの。
Google やその他のクラウド業者と違って Facebook は AI を直接売り物にしていない。だから遠慮なくモデルをオープンにできるのかもしれない。戦略的に Caffe のモデルをバンバン公開してマインドシェアを狙う。Open Compute と同じアプローチか。
などと感心していたら、最新の成果たる CNN translation のモデルは Torch ベースだった。邪推してすまぬ・・・他の会社は隣の芝で、なんかすごい戦略を持ってるように見えるのだよ・・・。
それはさておき自分のデータセットでモデルを fine tune できるのだとすると、世間の画像認識 API みたいな切り口はちょっと制限が強すぎる気がする。将来は課金すると追加で training data を登録できるようになると面白いね。
Convolutional Networks.
おもったほど新しい発見はなかった。NN4ML で読まされた LaNet や AlexNet の paper がすごいよく書けていたせいか、既にまあまあよく理解できていたっぽい。CNN って基本的なところはあまり難しくない割に強力で、お得感があるよね。
とはいえ復習としてはよかったし、理論的な位置づけも補強された。あと Neurosciene との関係についての節は読み物として面白かった。網膜の裏の神経というのはある種の CNN で、それがどんな kernel なのかを調べた人がいる、そしてその kernel によって学習される feature は CNN が学習してる feature と結構似てるんだよ、みたいな。やばい。
具体的なアーキテクチャの話が全然ないのはやや不満。rapidly moving だから本として記録しても仕方ないから、とかかいてあるけど、一個くらい実例の walk though をやってくれてもいいのにね。
あと CNN は kernel のサイズが画像サイズと独立だから異なるサイズの画像をつかって learning できるのだよ、みたいな話があって、しかしそんな例みたことないし想像もつかないなと調べてみたらちょっと大変そうだった。
元ネタを読む。少しはわかった。なぜこれがすごく効くのか数学的に理解できたかというとまったくそんなことはないけれど、少なくともなにをしているかはわかったはず。大局的になんかするわけではなく、 BN のレイヤを挟むだけの局所的なものだとわかったのはよかった。単に normalize するだけでなく、その normalization を cancel するような謎のパラメタを学習させるところがすごいというか、ちょっと狂ってるなと思う。
それにしても実験結果が豪華。Dropout を過去のものにする(こともある)と主張するのもそれなりに説得力がある。ただ CNN の場合はこうしろだの色々実用上は繊細なところがある様子も伺える。使うとなったら真面目に読み直さないとダメそう。というかまあ、サンプルをコピペするんだろうな。
チートがてら TensorFlow の実装をみてみたら辛い感じ・・・。TF 固有の読みづらさは差し引くとして、まず Batch Renormalization という最新の成果が雑に突っ込まれ可読性を損ねている。そして mean と variance を moving average として更新している。え、そんな話だったっけ・・・?と思って論文を読みなおすとサラっとかいてあった・・・いや別の話か・・・いずれにせよコードみないとわからんだろこれ・・・。しかし moving average で内部状態が変化するような layer の微分可能性とかどうなってるんだろうか。まったくなぞ。
コアの実装はシンプルだけど、いずれにせよ自分のにわか TF 力では歯が立たず。まあそのうち出直します。
Optimization for Training Deep Models.
数学がきついかと思いきや、わりと大丈夫だった。なぜなら難しい話題は適当にはぐらかされているから・・・。そして前章につづき期待していたより面白かった。
まず deep network training の難しさは local minima ではないという主張が面白い。Local minima かどうかを調べる方法 (gradient の norm を求める) や、local minima が相対的には大した問題ではない話など。数学的に厳密的な議論ではないけれど、なるほどなーと思う。
各種アルゴリズムについては Coursera の授業ではさっぱりわけわからなかった RMSProp がすんなりわかってよかった。やはり cover-to-cover で順番に読んでいくの重要。つまみ食いだとわからない話もわかる。しかし learning rate の調整をこんなにがんばらないといけないのは大変だよな。
BFGS のような二回微分を使う方法たち。自分はこの手の方法は Tensorflow などの Ops が二回微分を定義しないと使えないからダメじゃんと思っていたがそれは誤解で、実際は近似的な手法だと知った。
一方でこの手の強力な optimization algorithms を使うより train しやすいモデルが重要だ、という警告は面白い。別の言い方をすると、NN を blackbox として捉える旧来の optimization より NN の構造を exploit する pre-training や skip layer connection の方が強力という話。当たり前といえば当たり前だけれど、abstraction の壁を破ってチューニングすると大きな成果がでる展開は好き。もっとやれと思う。そういう意味で後半にちらっとでてきたもののさっぱりわからなかった Batch normalization は要復習。
前章とあわせ、関数の形に関する議論や、ネットワークの中を gradient が propagate していく(そして vanish/explode しないよう工夫する)みたいな概念にちょっと慣れてきた気がする。
Goodfellow 7.11 の (7.35) がなぜ ensemble が機能するかを説明している。要するにエラーの式の中に covariance が出てきてそれが (良い ensemble model では) 小さくなるから、という話をする。(e0+e1+e2)^2 を図に書いてみると、斜線でない部分の値が covariance の力で本来の面積より小さくなる。
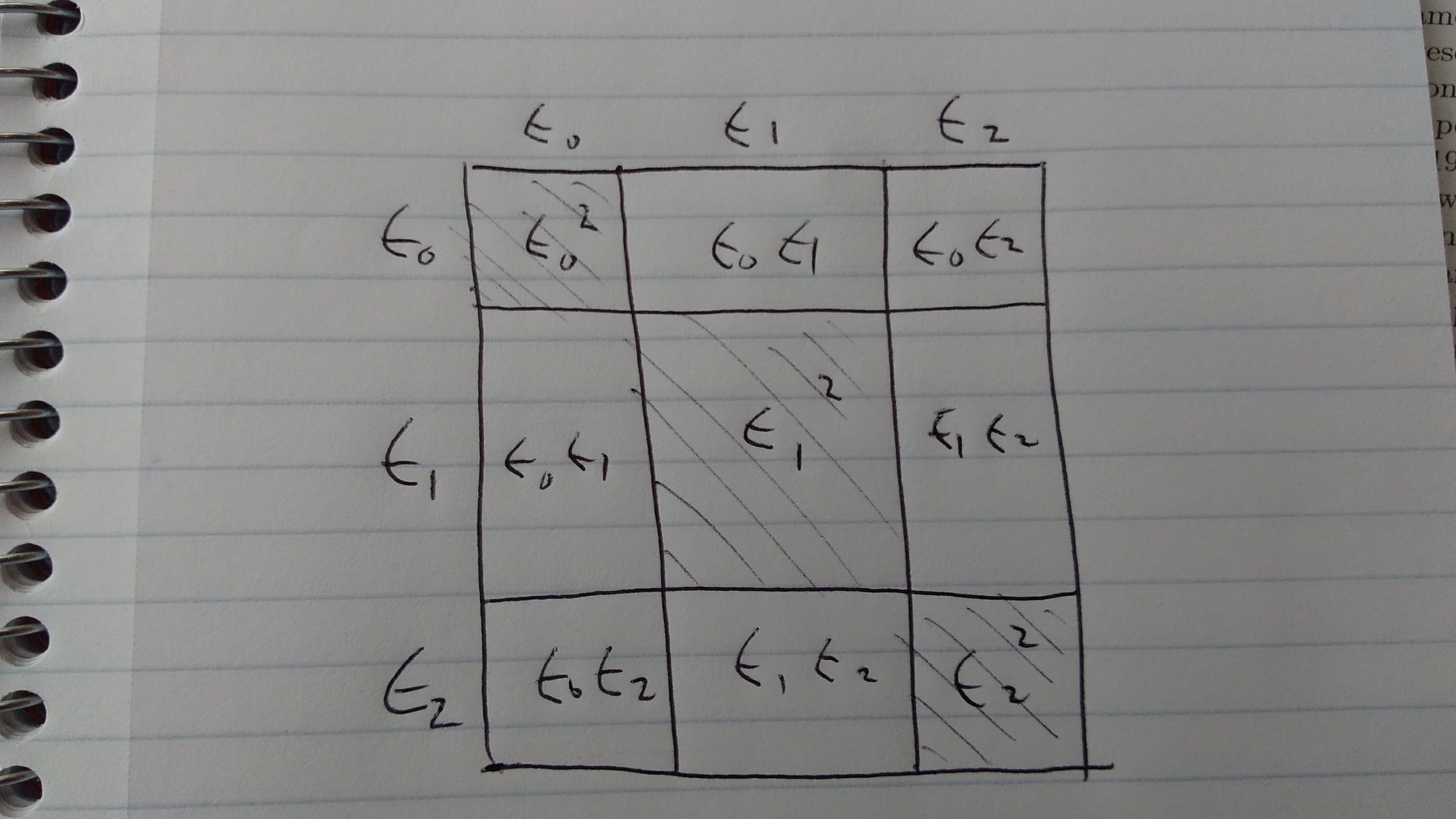
いまいち納得がいかなかったけれど、考えているうち個々の e が確率変数だから単純な実数のようには振る舞わない事実に段々と納得してきた。確率勉強しないとな・・・。
週に一章すすむのがせいぜいという悲しさよ・・・。
Regularization. 大して興味を持っていなかったのでぼんやり読んでいたら、思ったより面白かった。まず Dropout が丁寧に説明されている。TensorFlow 入門とかでやったときはこれは不思議なものだなーと天下り的に理解し、Coursra NN4ML の授業で少し理解できたところ、この章でもう一段理解が深まった。Dropout すごいね。計算量をケチれるだけでもすごいけれど、入力だけでなく様々な段階の representation にノイズを差し込めるというのも NN の性質をうまく活かしていてよい。
そのほか素人目には雑な思いつきにか見えない手法たちの理論的裏付けが軽く説明されているのもよかった。Early Stopping は L2 regularization の仲間だし、Data argumentation も adversarial training も tangent propagation だ、といわれるとなるほどと思う。まあ証明にはついてけないのだけれど、こういう雑にしか見えない方法もちゃんと reason されていることがわり deep learning も世間で言うほどデタラメカーゴカルトでもないと信頼が高まる。こういう demythification 体験は読書のやる気につながってよい。でも Manifold Hypothesis とかが完全に腑に落ちて身体的なレベルで理解できてないと、本当の意味でわかってるとは言えないなとも思う。
Goodfellow 本 読書記録。
Chapter 6 は feed forward network. 前読んだ時は backpropagation の節ばかり読んでいたけれど、その手前にある activation function や loss funciton の話も結構丁寧にかいてあった。 自分はなんで sigmoid がダメで ReLU なのかわかってなかったけれど、saturation があるでしょ、といわれるとそのとおりだなと思う。
最後にある Historical Notes の節もよかった。現代の NN は昔と何が違うのか、データサイズや計算機の性能はもちろんだけれど、Maximum Log Likelihood / Cross-entropy の普及と ReLU の登場もでかかったという。授業をぼんやり見てるだけだと気づけないところなので読んだ甲斐があった。
Backpropagation は、わかってから読むと大変明快に書いてあるけれどわからない人にわかりやすくは書いてない。去年がんばった甲斐あって理解はできたが、新しい発見もなし。でもこれが理解できるようになったのはよかったなあ。プログラミングでいうと再帰とかポインタとかクロージャとかシステムコールとか、そういうやつらが理解できた時の喜びに似ている。
Part 1, 5.5 あたり。
誤差を最小化するのではなく、モデル(確率モデル)上でのデータの likelihood を最大化する、という形で学習を定義すると色々捗るという話。
Mean squared error も実際はガウス分布の likelihood と等価であるとか、よくわかってなかったので読み直す。ついでに cross-entropy も等価だとかいいだすし。何度か読み直し、Python でグラフを書いてみたりもして、ようやくメンタルモデルができてきた。
Bayesian 方面から来るとこの方が馴染みやすいのかもしれないけど、何かと確率変数で物事を定式化していくスタイルはなかなか馴染めなずしんどい。ガチガチに高階関数なコードに馴染めないのと似ている。なんか「おまえらが Rx だなんだと有難がっているものは全部モナドだ!バーン!」みたいな気分。もうちょっと適応したいもんです。Monad も Bayes も。
ML diary.
Deep learning, どういう話かすっかり忘れてしまったので Goodfellow を読み直す。今回は頭から順番に読む。ようやく Part 1 読了。Part 1 は Deep Learning の前段階である線形代数だのなんだのを復習する内容。
まあ読まなくてもいいと思う。知っている内容は知っているし、知らない話は短く書かれてもわからない。
あとあと必要とされる知識のうち自分が知らないものを把握する役にはたった。自分は確率、情報理論が怪しい。数値計算は怪しいけれど、まあこれはなくても大丈夫かな。なんとなく。線形代数はたぶん大丈夫。機械学習基礎、きっと大丈夫。
確率と情報理論は主に Part 3 で必要とされた記憶がある。つまり Part 2 までは読み進められるけれど Part 3 を読む前にはこれらの前提知識を勉強する必要があるということ。それがわかったのはよかった。
明日から本編である Part 2 に入れるのはうれしい。読み切るのにどれくらいかかるかねえ。
関係ないけど Ian Goodfellow 氏、いつのまにか OpenAI から Google に移籍していた。時代に欲されている人は自由だなあ。
ML 入門 Diary 略して MLD. 実際は ML というか NN だけど。
ここ数日で GCE で Jupyter とかをする用のインスタンスの provisioning 自動化をした。
- 前回 AWS でやっていた時は Vagrant をつかっていたけれど、今回は GCE の Startup Script と若干の手動作業に移行した。Vagrant は大げさ過ぎることに気がついたため。サーバの deploy と違って Jupyter 環境にはどのみち SSH でログインして色々作業するので、完全に自動化しなくてもまあいいかな、と思うに至った。
- Python は pyenv のみで virtualenv はナシ。環境を作り直したい時は VM ごと作りなおせば良いと割り切る。virtualenv って activate とかが面倒だし。
- GPU の有無は、いちおう GPU を使えることは確認しつつ最初は CPU だけにしておく。お金をけちるため。
- GCE はインスタンス構築後に device type (CPU 数とか) を変えられることに気づいた。各種準備などをしている時はCPU数を減らし、トレーニングを回す段になったら CPU を増やす、とかができる。残念ながら GPU の付け外しはできない。そのうちできるようになると期待。データは独立した permanent disk に置きインスタンスを作りなおすでも理論上はいいんだけど、コマンド一行で変更できるならその方がラク。
- Jupyter notebook でなく Jupyter Lab を試している。荒削りながら Koding をしょぼく軽くしたような感じで、けっこう良い。Notebook 機能だけでなくテキストエディタとターミナルがブラウザからさわれるようになる。上で SSH すると書いたけれど、実は Jupyter Lab の起動までを全部自動化した方がいいかもしれない。オープンソース JS プログラマは Atom とかほっといて Jupyter Lab の開発を手伝って欲しいもんです。
作った環境の使用を兼ねて Keras をさわってみる。といってもサンプルをコピペして動かしただけ。TF を直に触るよりはだいぶラク。自分で shape を計算する手間がだいぶ減るし、単純にコード量も少ない。自分がクールな ML アルゴリズムを発明する日は来ないだろうという現実を踏まえると、このレイヤからプログラミングを始めても良い気がする。アルゴリズムへの理解は深まらないかもしれないけれど、実際に動かすまでの距離は短い方がやる気を出しやすいからね。
一方で、自分は Keras が面倒を見てくれないレイヤにも苦手なものが多いと気付く。ML な基本的な作業、たとえばデータの前処理、精度の評価、hyperparameter の探索など。前ちらっと Kaggle 入門を試した時の理解によるとそのへんは sklearn が面倒を見てくれるっぽい。そのうち入門しないといけなそう。